Capítulo 1 Escala
1.1 Apresentação
Nesta capitulo vamos entender a importância de escala na ecologia da paisagem através cálculos com a proporção de floresta. Durante o capitulo você aprenderá a
- Alterar escala (resolução e extensão espacial),
- Calcular a área de uma classe de habitat,
- Desenvolve uma comparação multiescala.
É muito importante ficar claro para você o que é escala (e o que não é!), e qual a importância desse conceito na elaboração do desenho amostral, na coleta de dados, nas análises e na tomada de decisão. Nesse tutorial usaremos conteudo baseado no Capítulo 2 do livro Spatial Ecology and Conservation Modeling (Fletcher and Fortin 2018) e “Tutorial Escala” do Dr. Alexandre Martensen.
Para ajudar a acompanhar e entender os exemplos no capítulo, você deve ler os seguintes artigos:
Best, J. 2019.
Anthropogenic stresses on the world’s big rivers. Nature Geoscience 12, 7–21. https://doi.org/10.1038/s41561-018-0262-xRaffo DCD, Norris D, Hartz SM, Michalski F. 2022.
Anthropogenic influences on the distribution of a threatened apex-predator around sustainable-use reserves following hydropower dam installation. PeerJ 10:e14287 https://doi.org/10.7717/peerj.14287Bárcenas‐García, A., Michalski, F., Gibbs, J. P., & Norris, D. (2022). Amazonian run‐of‐river dam reservoir impacts underestimated: Evidence from a before–after control–impact study of freshwater turtle nesting areas. Aquatic Conservation: Marine and Freshwater Ecosystems, 32(3), 508-522. https://doi.org/10.1002/aqc.3775
Sá‐Oliveira JC, Hawes JE, Isaac‐Nahum VJ, Peres C 2015.
Upstream and downstream responses of fish assemblages to an eastern Amazonian hydroelectric dam. Freshwater biology. Oct;60(10):2037-50. https://doi.org/10.1111/fwb.12628
1.2 Escala: breve definação
Todos os processos e padrões ecológicos têm uma dimensão temporal e espacial. Assim sendo, o conceito de escala não somente representar essas dimensões, mas também, ajudar nos apresentá-los de uma forma que facilite o entendimento sobre os processos e padrões sendo estudados.
Na ecologia o termo escala refere-se à dimensão ou domínio espaço-temporal de um processo ou padrão. Na ecologia da paisagem, a escala é frequentemente descrita por sua componentes: resolução e extensão.
- Resolução: menor unidade espacial de medida para um padrão ou processo.
- Extensão: descreve o comprimento ou tamanho de área sob investigação.
Resolução e extensão tendem a covariar – estudos com maior extensão tendem a ter resolução maiores também. Parte dessa covariância é prática: é difícil trabalhar em grandes extensões com dados coletados em tamanhos de resolução finos. No entanto, parte dessa covariância também é conceitual: muitas vezes em grandes extensões, podemos esperar que processos operando em resolução muito finos forneçam somente “ruído” e não dados/informações relevantes sobre os sistemas. Como os desafios computacionais diminuíram e a disponibilidade de dados de alta resolução aumentou, a covariância entre resolução e extensão nas investigações diminuiu.
Lembrando, na primeira aula, vimos que a escala espacial pode ser interpretada com base em três dimensoes:
- no fenômeno de interesse;
- na amostragem que ocorre;
e/ou
- na análise
Para que a Ecologia da Paisagem gere evidências científicas robustas e úteis, a escala nas três dimensões deve ser consistente e apropriada para o estudo. Incompatibilidade entre a escala de análise (definida por o pesquisador) e a escala de efeito (definida pelo verdadeiro relacionamento) representa uma versão do Problema de Unidade Areal Modificável (“Modifiable Areal Unit Problem” (Gehlke and Biehl 1934)), em que os resultados e a inferência torna-se um artefato do esquema de amostragem espacial em vez de um processo ecológico (Jelinski and Wu 1996; Wu and Li 2006).
Aqui nos concentramos na dimensão “análise”, e aprendemos como a escala espacial pode ser alterada e representada em modelos ecológicos.
1.3 Pacotes e dados
Em geral é necessário baixar alguns pacotes para que possamos fazer as nossas análises. Neste caso precisamos os seguintes pacotes, que deve esta instalado antes:
1.3.1 Pacotes
No R, carregar os pacotes necessarios com o codigo:
Caso os pacotes não tenham sido instalados, o R vai avisar atraves um mensagem tipo: Error in library(nomepacote) there is no package called nomepacote. Neste caso, para instalá-los consulte o Capítulo 6 ou os capitulos aqui Capitulo 4 instalação de pacotes e aqui Capitulo 4 pacotes . Prestando atenção nas diferenças para instalar um pacote como eprdados que vem do GitHub.
1.3.2 Dados
Vamos olhar um exemplo do mundo real. Uma pequena amostra do Rio Araguari, perto de Porto Grande. O ponto central é de longitude: -51.406312 latitude: 0.726236. Para visualizar o ponto no Google Earth: https://earthengine.google.com/timelapse#v=0.72154,-51.41543,11.8,latLng&t=2.24&ps=25&bt=19840101&et=20201231&startDwell=0&endDwell=0 .
Vammos trabalhar com os dados de MapBiomas, que produz mapeamento anual da cobertura e uso da terra no Brasil desde 1985. Os dados de MapBiomas vem no formato de raster, que tem uma classificação da terra feito a partir da classificação pixel a pixel de imagens das satélites Landsat. Todo processo é feito com algoritmos de aprendizagem de máquina (machine learning) através da plataforma Google Earth Engine, que oferece imensa capacidade de processamento na nuvem. Mais detalhes sobre a metodologia aqui: Metodologia MapBiomas.
Para carregar um arquivo raster trabalhamos com o pacote terra. O pacote tem varios funçoes para a análise e modelagem de dados geográficos. Nós podemos ler os dados de cobertura da terra no arquivo “.tif” com a função rast.
# arquivo no pacote "eprdados"
arquivo <- system.file("raster/amostra_mapbiomas_2020.tif",
package = "eprdados")
# carregar
ramostra <- rast(arquivo)Plotar para verificar.
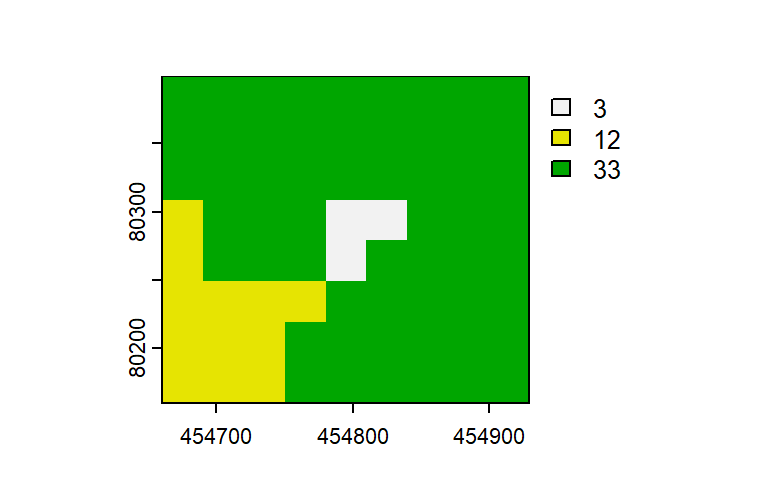
Figura 1.1: Mapbiomas 2020. Uma pequena amostra do Rio Araguari, perto de Porto Grande.
Podemos também verificar informações sobre o raster (metadados) - simplesmente rodar o nome do objeto:
## class : SpatRaster
## dimensions : 8, 9, 1 (nrow, ncol, nlyr)
## resolution : 29.89281, 29.89281 (x, y)
## extent : 454659.8, 454928.9, 80160.06, 80399.2 (xmin, xmax, ymin, ymax)
## coord. ref. : SIRGAS 2000 / UTM zone 22N (EPSG:31976)
## source : amostra_mapbiomas_2020.tif
## name : mapbiomas_2020
## min value : 3
## max value : 33Isso nos mostra informações sobre os atributos da raster no objeto ramostra. As informações como escala espacial (resolução e extensão) e a sistema de coordenadas (SIRGAS 2000 / UTM zone 22N , EPSG:31976) são apresentados e representem os componentes conforme a proxima figura.
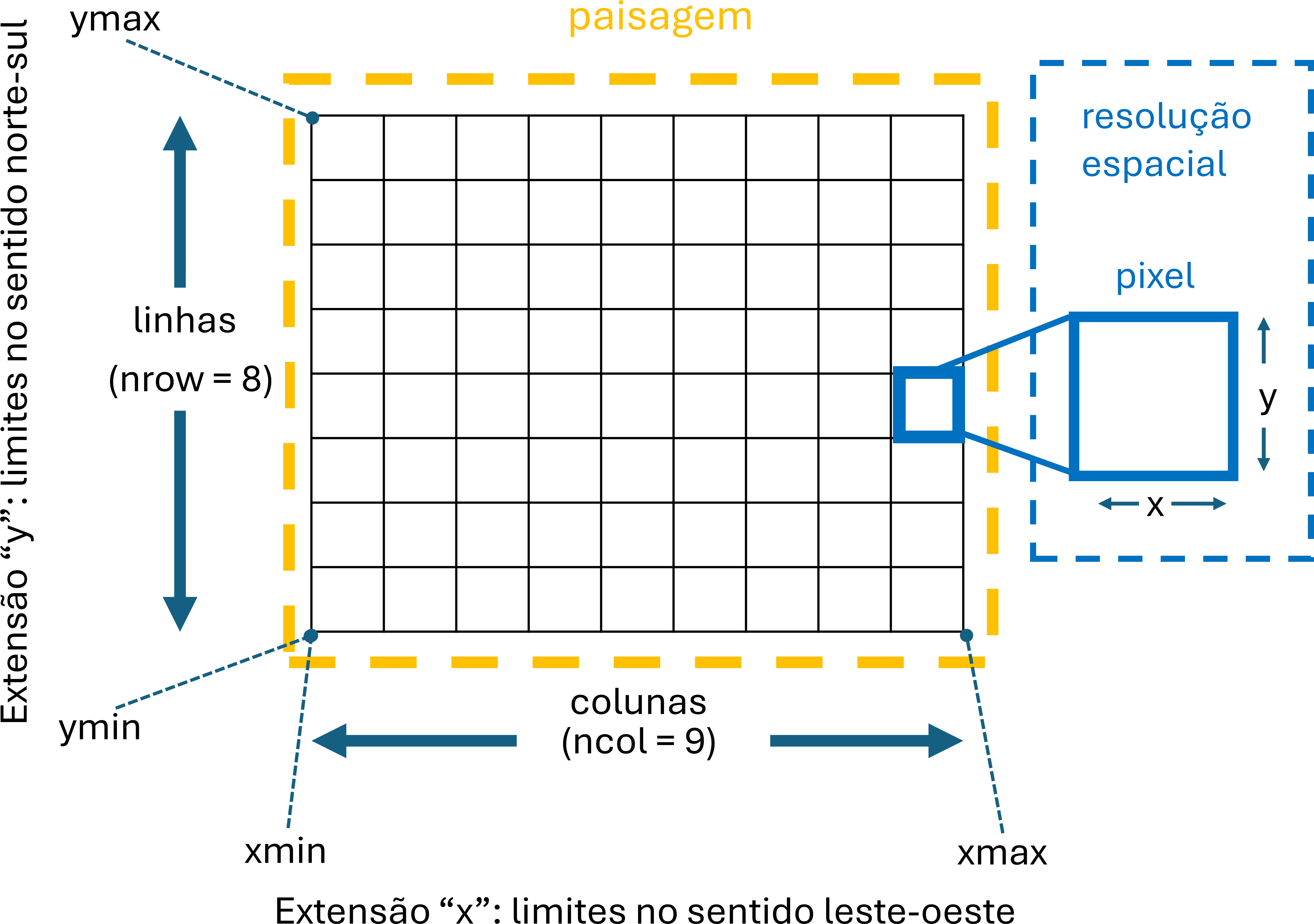
Figura 1.2: Componentes de uma raster e suas atributos no pacote terra.
Além disso é possível obter informações específicas através de funções específicas.
# Obter informações sobre escala espacial
# resolução, comprimento e largura do pixel em metros
res(ramostra)
# numero de colunas
ncol(ramostra)
# numero de linhas
nrow(ramostra)1.3.2.1 Pergunta 1
Sobre o objeto ramostra. Com base nos resultados obtidos, qual o área do pixel em metros quadrados? Qual o área total da paisagem em hectares e quilometros quadrados?
Olhando a mapa (Figura 1.1), existem três classes com valores de 3, 12 e 33. O objetivo principal não é de fazer mapas, mas, a visualização dos dados é um passo importante para verificar e entender os padrões. Portanto, segue exemplo mostrando uma forma de visualizar o arquivo de raster como mapa.
Para entender o que os valores (3, 12, 33) representam no mundo real precisamos de uma referência (legenda). Para a MapBiomas Coleção 6, arquivo: Cod_Class_legenda_Col6_MapBiomas_BR.pdf. Existe também arquivos para fazer as mapas com cores corretas em QGIS ou ArcGIS.
Olhando a legenda (Cod_Class_legenda_Col6_MapBiomas_BR.pdf), sabemos que “3”, “12” e “33” representem cobertura de “Formação Florestal”, “Formação Campestre”, e “Rio, Lago e Oceano”. Então podemos fazer um mapa mostrando tais informações.
Daqui pra frente vamos aproveitar uma forma mais elegante de apresentar mapas e gráficos. Isso seria atraves funçoes em 2 pacotes:
tmap é utilizado para gerar mapas temáticos
ggplot2, que faz parte do “tidyverse”, e é utilizado para produção de gráficos, e pode representar dados geoespacias.
Exemplos : Pacotes ggplot2 e tmap
Mais exemplos sobre o uso de ggplot2 no R cookbook : http://www.cookbook-r.com/Graphs/ .
E com mais exemplos de mapas e dados espaciais no R: sf e ggplot2 : https://www.r-spatial.org/r/2018/10/25/ggplot2-sf.html
Capitulo 9 no livro Geocomputation with R : https://geocompr.robinlovelace.net/adv-map.html
Primeiramente precisamos incluir as informações relevantes da legenda. Ou seja, incluir os nomes para cada valor de classe.
# legenda e cores na sequencia correta
classe_valor <- c(3, 12, 33)
classe_legenda <- c("Formação Florestal",
"Formação Campestre", "Rio, Lago e Oceano")
classe_cores <- c("#006400", "#B8AF4F", "#0000FF") Agora podemos fazer o mapa com as classes e os cores seguindo o padrão recomendado pela MapBiomas para Coleção 6.
tm_shape(ramostra) +
tm_raster(style = "cat",
palette = c("3" = "#006400", "12" ="#B8AF4F",
"33"= "#0000FF"), legend.show = FALSE) +
tm_grid(labels.format = list(big.mark = "")) +
tm_add_legend(type = "fill", labels = classe_legenda,
col = classe_cores, title = "Classe") +
tm_compass(position = c("right", "bottom")) +
tm_scale_bar(breaks = c(0, 0.05, 0.1), text.size = 1,
text.color = "white", position=c("right", "bottom")) +
tm_layout(legend.position = c("right","top"),legend.bg.color = "white")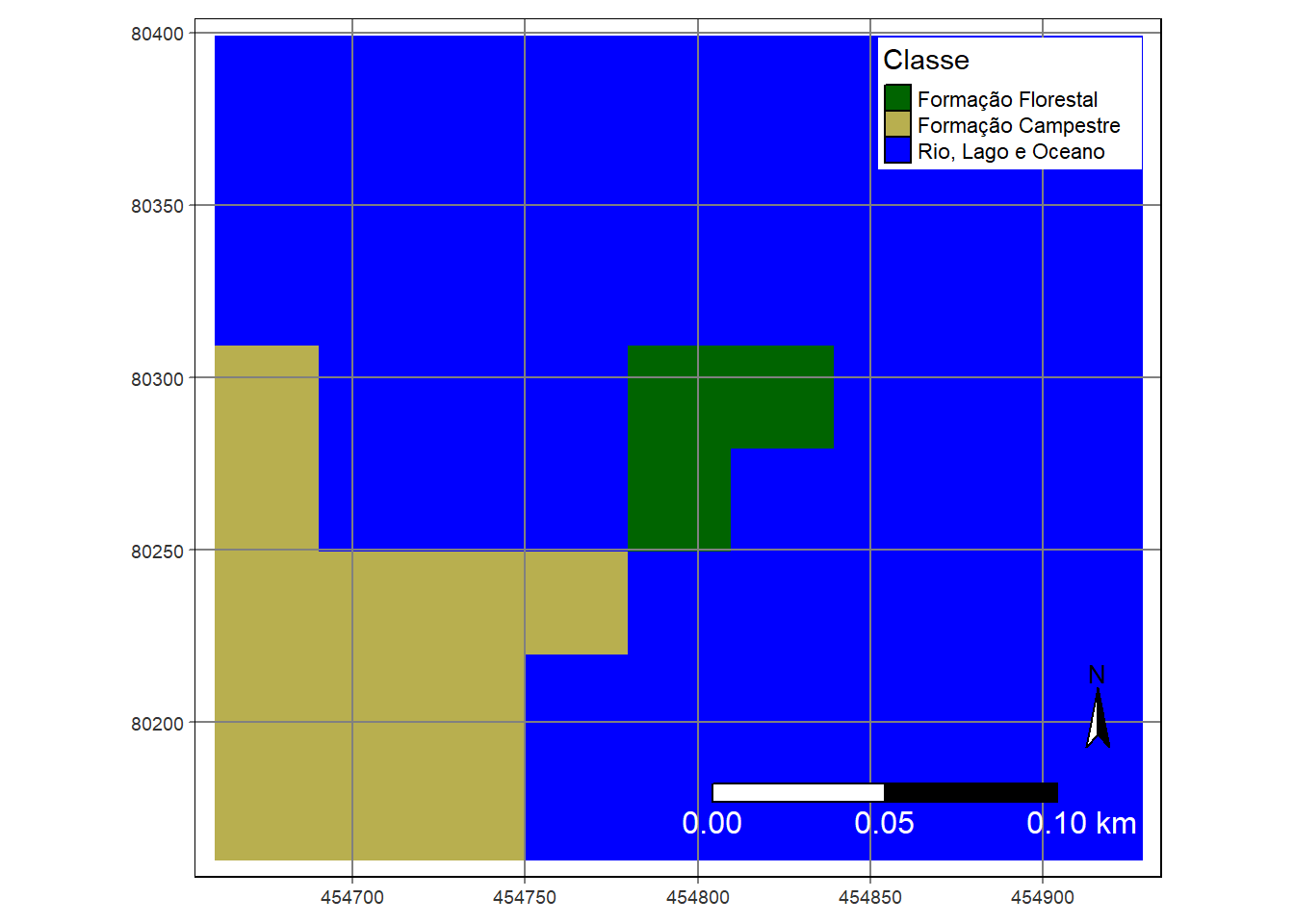
Figura 1.3: Paisagem com valores e classes de cobertura da terra. Mapbiomas 2020. Uma pequena amostra do Rio Araguari, perto de Porto Grande.
1.4 Alterando a resolução
Alterando a resolução serve como exemplo mostrando como os passos/etapas/cálculos mude dependendo o tipo de dados. Ou seja, é preciso adotar metodologias diferentes para dados categóricos (por exemplo classificação de cobertura da terra) e dados contínuos (por exemplo distância até rio).
Figura 1.4: Comparação de tamanhos de pixels pequenos e grandes. Mostrando diferenças causadas pela agregação de 4 pixels em 1.
Alterando a resolução às vezes seria necessário, por exemplo, quando preciso padronizar dados/imagens oriundos de fontes diferentes com resoluções diferentes e/ou para reduzir a complexidade da modelagem. Lembrando - em cada nível de resolução, são observáveis processos e padrões que não podem necessariamente ser inferidos daqueles abaixo ou acima.
A principal razão para tornar o mapa mais grosseiro é traduzi-lo para uma resolução de dados coletados em campo que estamos usando para fazer inferências. Por exemplo, se os dados foram coletados ao longo de dois transectos de 200 x 100 m dentro de manchas florestais. Se desejarmos fazer previsões das relações espécie-ambiente, podemos querer que o grão do nosso mapa reflita o grão da amostragem. Consequentemente, gostaríamos que o mapa tivesse um grão aproximado de 200 x 200 m.
Ao escolher um tamanho de pixel apropriado, equilibre a resolução espacial desejada – com base na unidade mínima de mapeamento das variaveis que você precisa analisar – com requisitos práticos para exibição rápida, tempo de processamento e armazenamento. Essencialmente, num SIG, os resultados são tão precisos quanto o conjunto de dados menos preciso. Se você estiver usando um conjunto de dados classificados derivado de imagens de satélite com resolução de 30 metros, o uso de um modelo digital de elevação ou outros dados auxiliares com resolução mais alta, como 10 metros, pode ser desnecessário. Quanto mais homogênea for uma área para variáveis críticas, como topografia e cobertura, maior poderá ser o tamanho da célula sem afetar a precisão.
Agora iremos degradar a resolução desses dados, ou seja, iremos alterar o tamanho dos pixels. Como exemplo, iremos juntar (agregar) 3 pixels em um único pixel. Como você acha que podemos fazer isso? Quais valores esse pixel que vai substituir os 3 originais deve ter? Existem diversas maneiras de se fazer isso, como por exemplo através a média ou valor modal (valor mais comum). O valor mais comum da área, é particularmente adequado quando temos um mapa categórico, como por exemplo a classificação do MapBiomas. Segue exemplo de codigo para agregar com a média e o valor mais frequente (modal).
# Média
ramostra_media <- aggregate(ramostra, fact=3, fun="mean")
ramostra_media <- resample(ramostra, ramostra_media)
# Modal
ramostra_modal <- aggregate(ramostra, fact=3, fun="modal")
ramostra_modal <- resample(ramostra, ramostra_modal, method="near")1.4.0.1 Pergunta 2
Utilizando as funções disponíveis no pacote tmap, crie mapas temáticos dos objetos ramostra_media e ramostra_modal. Inclua cópias do seu código e mapas na sua resposta. Você pode usar o printscreen para mostrar o RStudio com seu código e mapas.
Visualizar os resultados apresentados em Figura 1.4. Os valores calculados pela média não fazem sentido para uma classificação categórica. Os valores calculados pela modal são consistentes com o original e fazem sentido.
Em cada nível de resolução, são observáveis processos e padrões que não podem necessariamente ser inferidos daqueles abaixo ou acima. Aqui por exemplo, mudamos a proporção de cobertura florestal em nossa pequeno paisagem quando juntamos 3 pixels em um único: a proporção de floresta moudou de 4% (3/72) para 11% (1/9). Ou seja, com cada passo mudamos a representção do mundo.
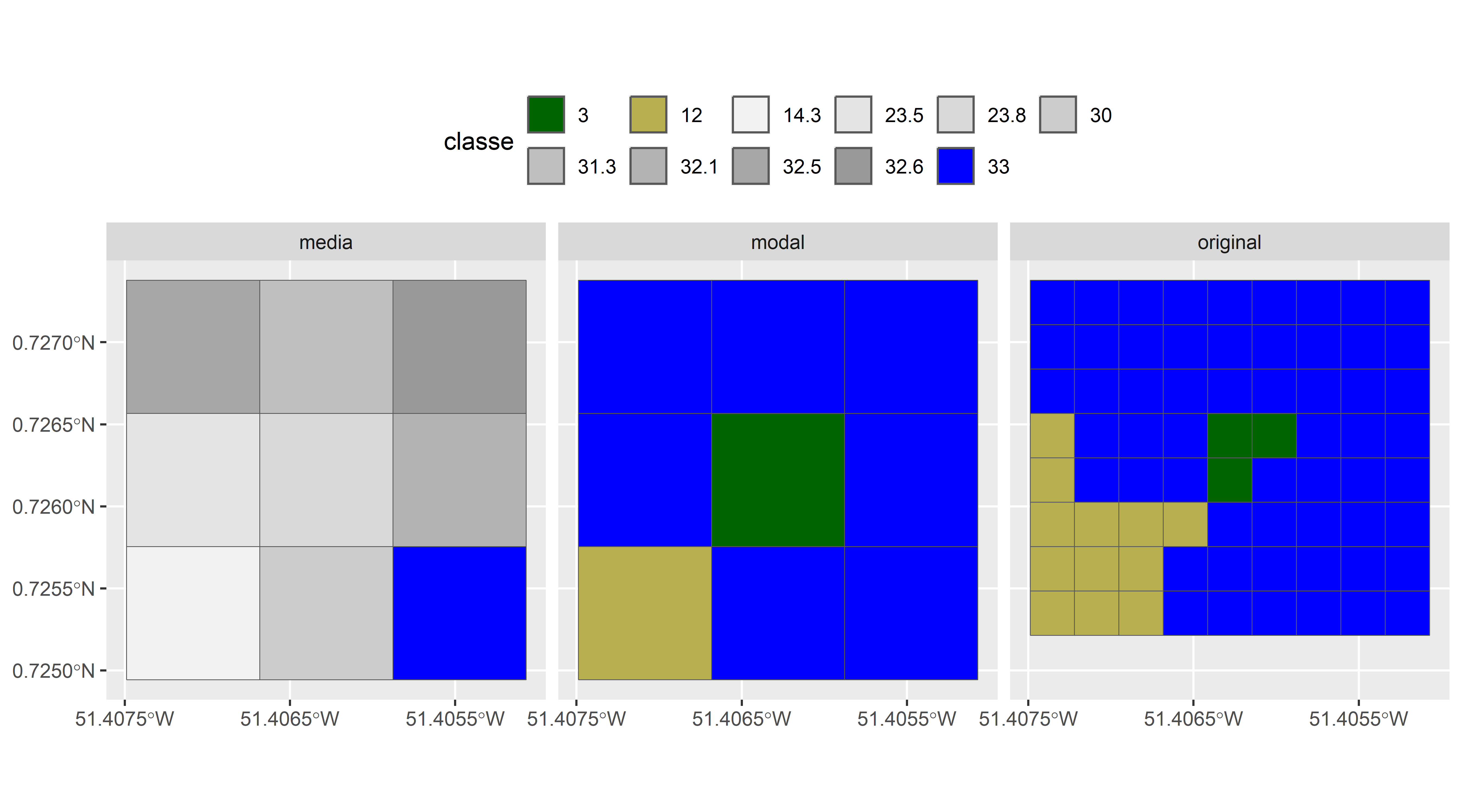
Figura 1.5: Mudanças causadas pela agregação.
1.5 Escala espacial e desenho amostral
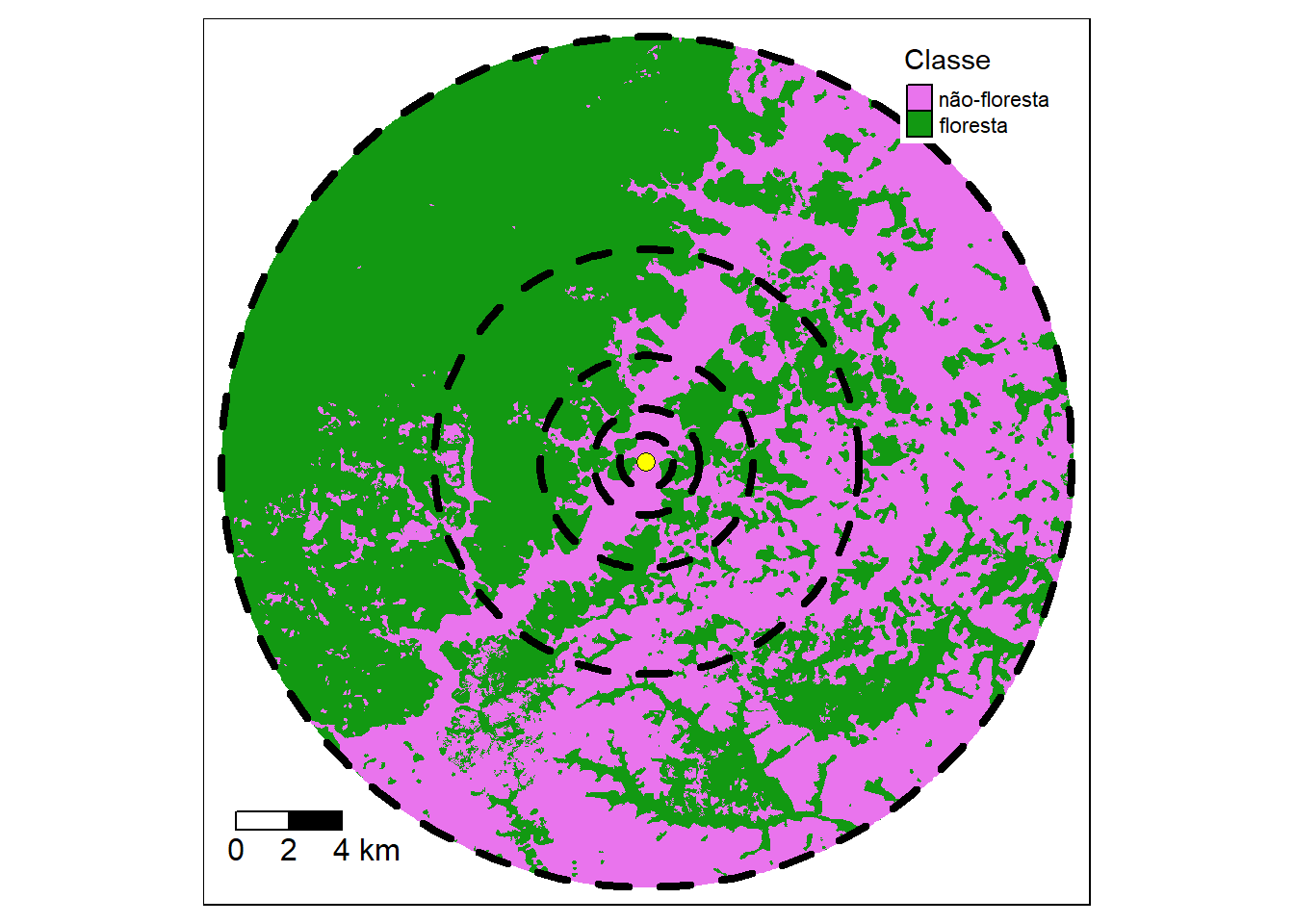
Figura 1.6: A cobertura florestal ao redor de um ponto de amostragem pode variar em escalas diferentes. Para entender essas variações, podemos criar buffers circulares de diferentes extensões ao redor dos pontos de amostragem. Esses buffers representam áreas de diferentes tamanhos ao redor de cada ponto. Quantificando a quantidade de floresta que ocorre em cada buffer, podemos obter uma visão geral da escala em que a cobertura florestal muda ao redor dos pontos de amostragem. Por exemplo, podemos descobrir que a cobertura florestal é mais alta dentro de um buffer de 5 km do que em um buffer de 10 km.
Dado o papel que a escala pode desempenhar em nossa compreensão dos padrões e processos ecológicos, como escala deve ser considerada no desenho do estudo? Claramente, a resposta a esta pergunta irá variar dependendo dos fenômenos de interesse, mas ecologistas e estatísticos têm forneceu algumas orientações importantes. As questões-chave incluem o tamanho da unidade de amostragem (resolução), o tipo de unidade de amostra e localizações da unidade de amostra, incluindo o espacamento entre as amostras (distância entre as amostras) e o tamanho da área de estudo.
Com a disponibilidade de imagens de satélite é possível responder questões importantes relacionadas ao desenho do estudo antes de qualquer trabalho de campo. Uma tecnica de geoprocessamento (zona tampão - Buffers) é um dos mais frequentemente adotados para quantificar escala espacial na ecologia da paisagem.
O objetivo é criar buffers circulares de diferentes extensões ao redor dos sitios de amostragem (pontos, pixels, manchas, transetos lineares etc). Aqui, vamos entender a escala em que a cobertura de floresta muda ao redor dos rios. Para isso, quantificamos a quantidade de floresta que ocorre em várias distâncias em pontos ao longo dos rios a montante das hidrelétricas no Rio Araguari. Para ilustrar esta abordagem geral, usamos o banco de dados MapBiomas Coleção 6 de 2020, e vincule esses dados de cobertura da terra aos pontos de amostragem em rios.
1.5.1 Obter e carregar dados (vectores)
Antes de quantificar a quantidade de floresta, precisamos carregar os dados de rios e pontos de amostragem. O formato de vector é diferente de “tif” (raster), portanto o processo de importação é diferente. Aqui, nós só precisamos de duas dessas camadas, ambos do pacote ‘eprdados’: “rio_linhacentral” e “rio_pontos”. A primeira camada de dados contém o eixo central de 260 km de rios a montante da Barragem Cachoeira Caldeirão. Os dados foram obtidos a partir de registros de trajetória GPS durante levantamentos de barco. Os rios foram divididos em 52 seções, cada uma com aproximadamente 5 km de extensão. A segunda camada de dados, “rio_pontos”, contém 52 pontos espaçados regularmente ao longo dos rios. Cada ponto está localizado a aproximadamente 5 km de distância do ponto anterior.
1.5.2 Visualizar os arquivos (camadas vector)
Visualizar para verificar. Mapa com ambos a linha central e pontos de rios em trechos de 5km.
ggplot(rio_linhacentral) +
geom_sf(aes(color=rio)) +
geom_sf(data = rio_pontos, shape=21, aes(fill=zone))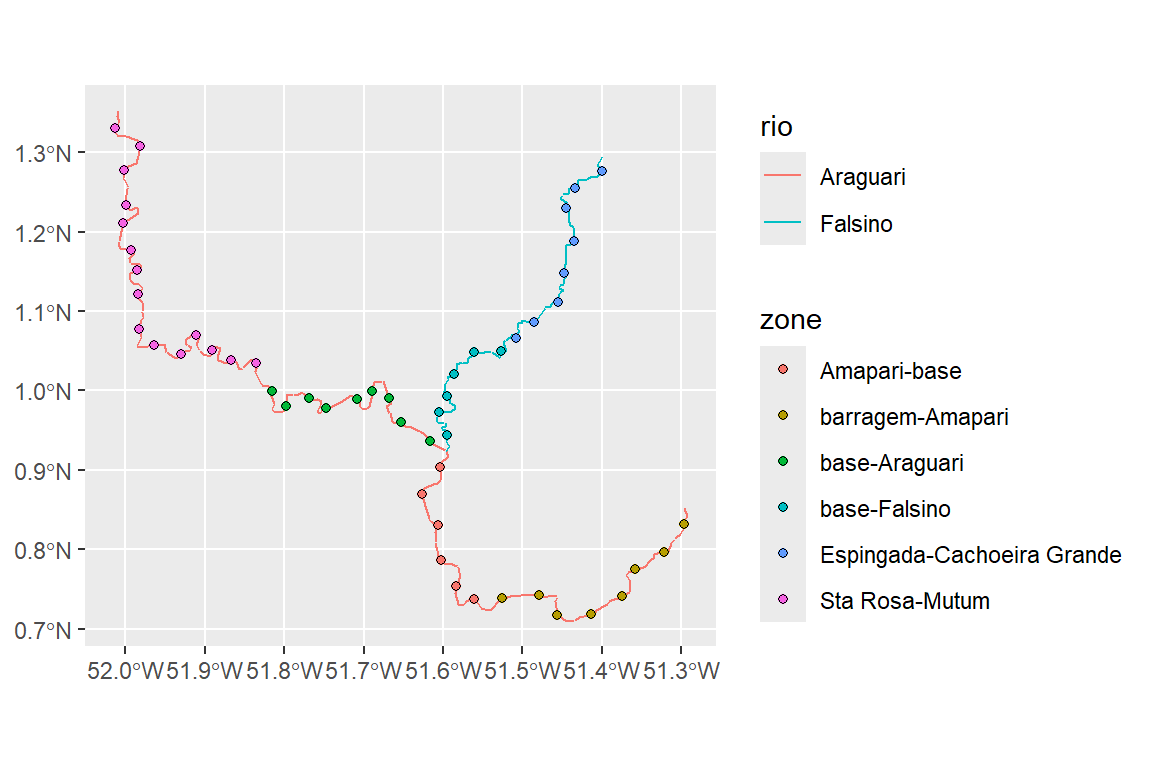
Figura 1.7: Pontos ao longo dos rios a montante das hidrelétricas no Rio Araguari.
Mapa interativo (funcione somente com internet) Mostrando agora com fundo de mapas “base” (OpenStreetMap/ESRI etc)
1.5.3 Obter e carregar dados (raster)
Mais uma vez vamos aproveitar os dados de MapBiomas. Agora um arquivo raster com cobertura de terra no entorno dos rios em 2020, (formato “.tif”, tamanho 1.3 MB).O código abaixo vai carregar os dados e criar o objeto “mapbiomas_2020”:
1.5.4 Visualizar os arquivos (camadas raster e vector)
Visualizar para verificar. É possível de visualizar varios camadas de raster e vetor juntos com funcões no pacote tmap (https://r-tmap.github.io/tmap-book/index.html).
# Passo necessario para agilizar o processamento
mapbiomas_2020_modal <- aggregate(mapbiomas_2020,
fact = 10,
fun = "modal")
# Plot
tm_shape(mapbiomas_2020_modal) +
tm_raster(title = "Classe", style = "cat", palette = "Set3") +
tm_shape(rio_linhacentral) +
tm_lines(col="blue") +
tm_shape(rio_pontos) +
tm_dots(size = 0.2, col = "yellow") +
tm_compass(position=c("left", "top")) +
tm_scale_bar(breaks = c(0, 25, 50), text.size = 1,
position=c("left", "bottom")) +
tm_layout(legend.position = c("right","top"), legend.bg.color="white")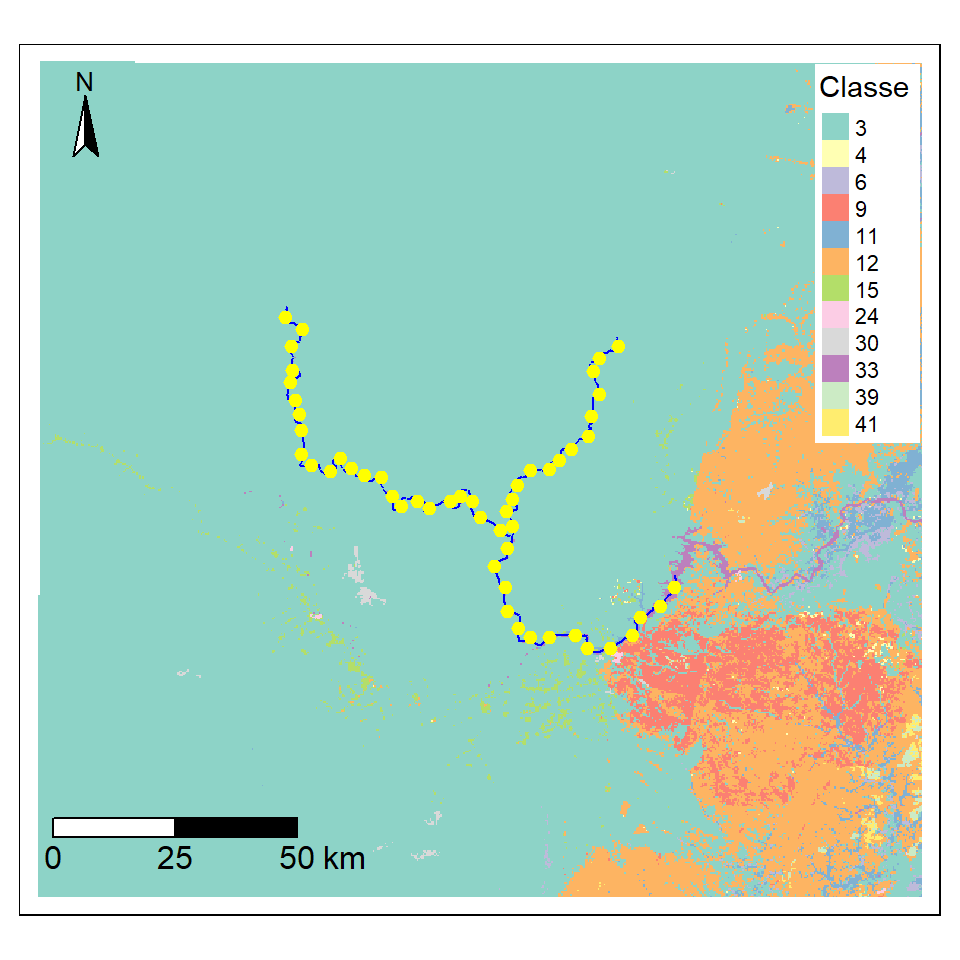
Figura 1.8: Cobertura da terra ao redor do Rio Araguari em 2020. Mostrando os pontos de amostragem (pontos amarelas) cada 5 quilômetros ao longo do rio.
1.5.5 Reclassificação
Para simplificar nossa avaliação de escala, reclassificamos a camada mapbiomas_2020 em uma camada binária de floresta/não-floresta. Essa tarefa de geoprocessamento pode ser realizada anteriormente usando SIG (QGIS). Aqui vamos reclassificar as categorias de cobertura da terra (agrupando diferentes áreas de cobertura florestal tipos) usando alguns comandos genéricos do R para criar uma nova camada com a cobertura de floresta em toda a região de estudo. Para isso, criamos um mapa do mesmo resolução e extensão, e então podemos redefinir os valores do mapa. Neste caso, queremos agrupar a cobertura da terra categorias 3 e 4 (Formação Florestal e Formação Savânica, respectivamente).
# criar uma nova camada de floresta
floresta_2020 <- mapbiomas_2020
# Com valor de 0
values(floresta_2020) <- 0
# Atualizar categorias florestais agrupados com valor de 1
floresta_2020[mapbiomas_2020 == 3 | mapbiomas_2020 == 4] <- 1 Vizualizar para verificar.
# Passo necessario para agilizar o processamento
floresta_2020_modal <- aggregate(floresta_2020,
fact=10,
fun="modal")
# Plot
tm_shape(floresta_2020_modal) +
tm_raster(style = "cat",
palette = c("0" = "#E974ED", "1" ="#129912"), legend.show = FALSE) +
tm_add_legend(type = "fill", labels = c("não-floresta", "floresta"),
col = c("#E974ED", "#129912"), title = "Classe") +
tm_shape(rio_linhacentral) +
tm_lines(col="blue") +
tm_shape(rio_pontos) +
tm_dots(size = 0.2, col = "yellow") +
tm_scale_bar(breaks = c(0, 25, 50), text.size = 1,
text.color = "white", position=c("left", "bottom")) +
tm_layout(legend.position = c("right","top"),legend.bg.color = "white")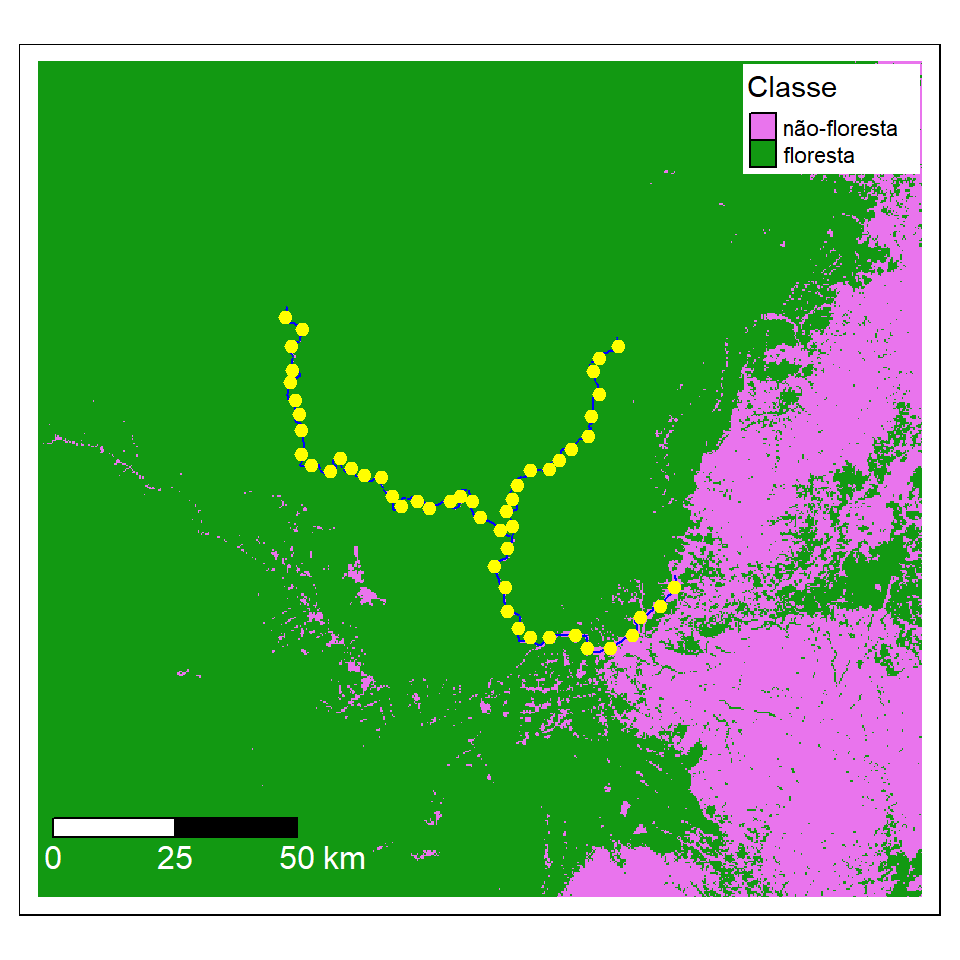
Figura 1.9: Floresta ao redor do Rio Araguari. MapBiomas 2020 reclassificado em floresta e não-floresta. Mostrando os pontos de amostragem (pontos amarelas) cada 5 quilômetros ao longo do rio.
1.6 Comparação multiescala
Em seguida, com as coordenadas dos pontos de amostragem, podemos calcular a quantidade de floresta que circunda cada local de amostragem em diferentes extensões. Primeiramente, vamos fazer so para um ponto, assim para entender o processo e os passos melhor.
rio_pontos_31976 <- st_transform(rio_pontos, 31976)
# Buffer
rio_pontos_31976_b1000 <- st_buffer(rio_pontos_31976[1, ], dist = 1000)
# Recorte com buffer de 1000 metros (mudando a extensão).
# Máscara (mask), assimos pixels fora do polígono sejam nulos.
buffer.forest1.1km <- terra::crop(floresta_2020, rio_pontos_31976_b1000,
snap="out", mask = TRUE)
names(buffer.forest1.1km) <- "forest_2020_1km"Vizualizar para verificar.
# Plot
tm_shape(buffer.forest1.1km) +
tm_raster(style = "cat",
palette = c("0" = "#E974ED",
"1" ="#129912"), legend.show = FALSE) +
tm_shape(rio_pontos_31976[1, ]) +
tm_symbols(shape =21, col = "yellow",
border.col = "black", border.lwd = 0.2, size=0.5) +
tm_shape(rio_pontos_31976_b1000) +
tm_borders(col = "black", lwd = 4, lty = "dashed") +
tm_add_legend(type = "fill", labels = c("não-floresta", "floresta"),
col = c("#E974ED", "#129912"), title = "Classe") +
tm_compass(position=c("left", "top")) +
tm_scale_bar(breaks = c(0, 0.5, 1), text.size = 1,
position=c("left", "bottom")) +
tm_layout(legend.position = c("right","top"), legend.bg.color = "white")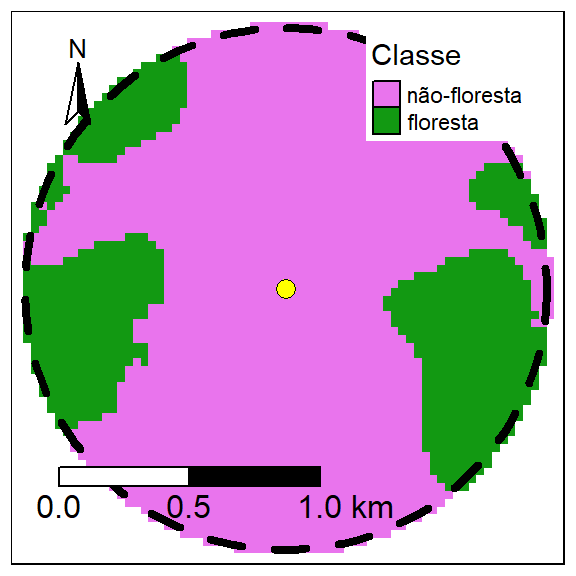
Figura 1.10: Ilustração da determinação da quantidade de habitat ao redor de um ponto. Para um determinada extensão, o habitat de interesse é isolado. Um buffer (linha tracejada) é colocado ao redor de um ponto (amarela) e o número de células (pixels) que contém o habitat é somado e multiplicado pela área de cada pixel.
1.6.0.1 Pergunta 4
Qual é a extensão em número de pixels desse recorte (buffer.forest1.1km)?
Temos valores de 0 (não-floresta) e 1 (floresta). Então, para saber a aréa de floresta podemos somar o número de células (pixels) que contém o habitat e multiplica pela área de cada pixel conforme o codigo:
# 1) Somatório.
# No caso igual o numero de pixels de floresta.
# Para todo a paisagem, somatorio "global".
# Não deve incluir pixels nulos, então use "na.rm = TRUE".
soma_floresta <- global(buffer.forest1.1km, "sum", na.rm = TRUE)
soma_floresta## sum
## forest_2020_1km 939# 2) Área de cada pixel.
# Sabemos o sistema de coordenadas (EPSG = 31976).
# EPSG 31976 é uma sistema projetado com unidade em metros.
buffer.forest1.1km## class : SpatRaster
## dimensions : 68, 68, 1 (nrow, ncol, nlyr)
## resolution : 29.89281, 29.89281 (x, y)
## extent : 465959.3, 467992, 90921.47, 92954.18 (xmin, xmax, ymin, ymax)
## coord. ref. : SIRGAS 2000 / UTM zone 22N (EPSG:31976)
## source(s) : memory
## varname : utm_cover_AP_rio_2020
## name : forest_2020_1km
## min value : 0
## max value : 1## [1] 893.5801# 3) Calculos de aréa.
# Aréa de floresta m2
area_floresta_m2 <- soma_floresta * area_pixel_m2
area_floresta_m2## sum
## forest_2020_1km 839071.7## sum
## forest_2020_1km 83.90717Para uma comparação multiescala, vamos repetir o mesmo processo, mas agora com distancias de 250, 500, 1000, 2000 e 4000 metros, doubrando a escala (extensão) em cada passo.
Figura 1.11: Cobertura florestal em extensões diferentes ao redor de um local de amostragem.
Aspectos quantitativos das paisagens mudam fundamentalmente com a escala. Por exemplo, nesse caso, parece que a proporção de floresta aumenta à medida que a extensão aumenta de 500 para 4000 metros. Esta percepção visual é confirmada pelos valores calculados, onde as áreas são:
- raio 250 m = 0 hectares de floresta
- raio 500 m = 6,3 hectares de floresta
- raio 1000 m = 84,3 hectares de floresta
- raio 2000 m = 502.6 hectares de floresta
- raio 4000 m = 3351.0 hectares de floresta
1.6.0.2 Pergunta 5
Usando os valores listadas acima de raio e área de floresta para os diferentes buffers circulares, calcule a proporção de floresta em cada uma das diferentes extensões de buffer. Apresente 1) os resultados incluindo cálculos. 2) um gráfico com valores de extensão no eixo x e proporção da floresta no eixo y. 3) Em menos de 200 palavras apresente a sua interpretação do gráfico.
1.6.0.3 Pergunta 6
A modelagem multiescala quantifica as condições do ambiente em múltiplas escalas alterando o resolução ou a extensão da análise e, em seguida, avaliando qual das escalas consideradas explica melhor um padrão ou processo. Escolha 1 espécie aquático e 1 espécie terrestre que ocorram na região a montante das hidrelétricas no Rio Araguari (especificando nome comum junto com o nome científico para ambos). Com base nas diferenças entre extensões (indicados no exemplo anterior) e as características funcionais das espécies (por exemplo área de vida), escolher as extensões mais adequadas para um estudo multiescala de cada espécie.
Essa foi a última pergunta.
Soluções dos exercícios: https://darrennorris.github.io/eprsol/solutions01_escala.html
1.7 Próximos passos: repetindo para muitas amostras.
Neste exemplo comparamos a área de floresta em torno de um único ponto de amostragem. Para calcular o mesmo para todos os 52 pontos, seriam necessárias varias repetições (52 pontos x 5 extensões = 260 repetições).
Poderíamos escrever código para executar esse processo automaticamente. Felizmente, alguém já escreveu funções para fazer isso e muito mais. O próximo tutorial sobre métricas de paisagem mostrará exemplos usando o pacote “landscapemetrics” (https://r-spatialecology.github.io/landscapemetrics/).