Capítulo 5 Garimpo do Lourenço
5.1 Apresentação
Mudanças na paisagem ao redor do Garimpo do Lourenço. Changes in the landscape surrounding the Lourenço gold mine.

Código de R e dados para calcular métricas de paisagem associadas com a exploração de recursos minerários.
O objetivo é calcular métricas de paisagem e descrever a composição e a configuração da paisagem no entorno do Garimpo do Lourenço.
As métricas de paisagem são a forma que os ecólogos de paisagem usam para descrever os padrões espaciais de paisagens para depois avaliar a influência destes padrões espaciais nos padrões e processos ecológicos.
Nesta exemplo (https://rpubs.com/darren75/lourenco) aprenderemos sobre como analisar a cobertura da terra com métricas de paisagem em R.
Este exemplo tem como base teórica o modelo “mancha-corredor-matriz” - uma representação da paisagem em manchas de habitat (fragmentos).
5.3 Área de estudo
Para alcançar o objetivo de caracterizar a paisagem no entorno do Garimpo do Lourenço, precisamos estabelecer a extensão da área de estudo. Isso seria estabelicida com base nos objetivos e estudos anteriores. Sabemos que atividades asociados com a mineração pode aumentar a perda da floresta até 70 km além dos limites do processo de mineração: Sonter et. al. 2017. Mining drives extensive deforestation in the Brazilian Amazon https://www.nature.com/articles/s41467-017-00557-w
Para visualizar um exemplo com a Extração de bauxita na Flona Saracá-Taquera: https://earthengine.google.com/timelapse/#v=-1.70085,-56.45017,8.939,latLng&t=2.70
E aqui com o Garimpo do Lourenço: https://earthengine.google.com/timelapse#v=2.2994,-51.68423,11.382,latLng&t=0.03
5.4 Dados
5.4.1 Ponto de referência (EPSG: 4326)
Aqui vamos incluir um raio de 20 km além do ponto de acesso para o Garimpo do Lourenço em 1985. Isso representa uma área quadrada de 40 x 40 km (1600 km2).
# Tabela de dados com coordenados de acesso em 1985.
acesso <- data.frame(nome = "garimpo do Lourenço",
coord_x = -51.630871,
coord_y = 2.318514)
# Converter para objeto espacial, com sistema de coordenados geográfica.
sf_acesso <- st_as_sf(acesso,
coords = c("coord_x", "coord_y"),
crs = 4326)Visualizar para verificar.
5.4.2 Ponto de referência (EPSG: 31976)
As análises da paisagem com o modelo “mancha-corredor-matriz” depende de uma classificação categórica. Portanto, deve optar para uma sistema de coordenados projetados, com pixels de área igual e com unidade em metros. Temos um raio de 20 km, que é um area geografica onde o retângulo envolvente é menor que um fuso UTM. Assim sendo, vamos adotar a sistema de coordenados projetados de datum SIRGAS 2000, especificamente EPSG:31976 (SIRGAS 2000/UTM zone 22N).
Precisamos então reprojetar o objeto original (em coordenados geográficas) para a sistema de coordenados projetados. Em seguida, vamos produzir um polígono com raio de 20 km no entorno do ponto.
# Reprojetar o ponto.
sf_acesso_utm <- st_transform(sf_acesso, crs = 31976)
# Polígono com raio de 500 metros no entorno do ponto.
sf_acesso_500m <- st_buffer(sf_acesso_utm, dist=500) |>
mutate(raio_km = 0.5)
# Polígono com raio de 1 km no entorno do ponto.
sf_acesso_1km <- st_buffer(sf_acesso_utm, dist=1000) |>
mutate(raio_km = 1)
# Polígono com raio de 2 km no entorno do ponto.
sf_acesso_2km <- st_buffer(sf_acesso_utm, dist=2000) |>
mutate(raio_km = 2)
# Polígono com raio de 4 km no entorno do ponto.
sf_acesso_4km <- st_buffer(sf_acesso_utm, dist=4000) |>
mutate(raio_km = 4)
# Polígono com raio de 20 km no entorno do ponto.
sf_acesso_20km <- st_buffer(sf_acesso_utm, dist=20000)
acesso_buffers <- bind_rows(sf_acesso_500m, sf_acesso_1km,
sf_acesso_2km, sf_acesso_4km)
5.4.4 Dados: MapBiomas cobertura da terra
Agora vamos olhar cobertura e uso da terra no espaco que preciso (área de estudo). Para isso, vamos utilizar um arquivo de raster do projeto MapBiomas com cobertura de terra ao redor do Garimpo do Lourenço em 1985. Este arquivo no formato raster, tem apenas valores inteiros, em que cada célula/pixel representa uma área considerada homogênea, como uso do solo ou tipo de vegetação. Arquivo “.tif” disponível aqui: utm_cover_AP_lorenco_1985.tif
Não vamos construir mapas, portanto os cores nas visualizações não corresponde ao mundo real (por exemplo, verde não é floresta). Para visualizar em QGIS preciso baixar um arquivo com a legenda e cores para Coleção¨6 (https://mapbiomas.org/codigos-de-legenda) e segue tutoriais: https://www.youtube.com/watch?v=WtyotodHK8E .
Este vez, a entrada de dados espaciais seria atraves a importação de um raster (arquivo de .tif). Lembre-se, para facilitar, os arquivos deve ficar no mesmo diretório do seu código (verifique com getwd()). Como nós já sabemos a sistema de coordenados desejadas, o geoprocessamento da raster foi concluído antes de começar com as análises da paisagem.
r1985 <- rast("utm_cover_AP_lorenco_1985.tif")
r1985
#class : SpatRaster
#dimensions : 1341, 1341, 1 (nrow, ncol, nlyr)
#resolution : 29.87713, 29.87713 (x, y)
#extent : 409829.5, 449894.7, 236241.1, 276306.3 (xmin, xmax, ymin, ymax)
#coord. ref. : SIRGAS 2000 / UTM zone 22N (EPSG:31976)
#source : utm_cover_AP_lorenco_1985.tif
#name : classification_1985
#min value : 3
#max value : 33 Ou use o função file.choose(), que faz a busca para arquivos.
## used (Mb) gc trigger (Mb) max used (Mb)
## Ncells 8678562 463.5 19594787 1046.5 19594787 1046.5
## Vcells 38247843 291.9 118462564 903.8 148077084 1129.8Agora que o arquivo foi importado, podemos visualizá- lo.
# Visualizar para verificar
# Gradiente de cores padrão não corresponde
# ao mundo real (por exemplo verde não é floresta)
plot(r1985, type="classes")
plot(sf_acesso_20km, add = TRUE, lty ="dashed", color = "black")
plot(sf_acesso_utm, add = TRUE, cex = 2, pch = 19, color = "black")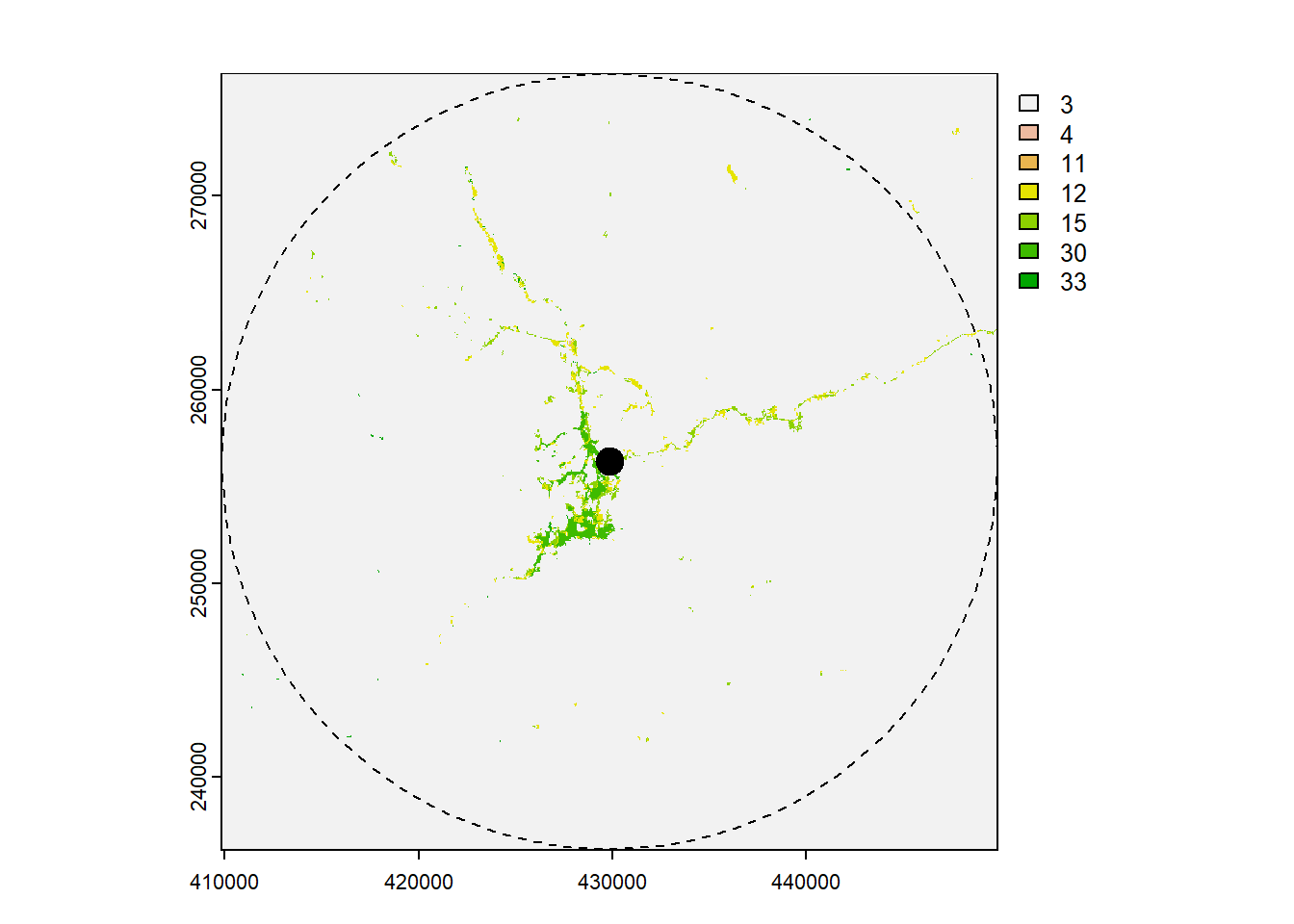
5.5 Calculo de métricas
Vamos olhar alguns exemplos de métricas para cada nível da análise:
- landscape (métricas para a paisagem como um todo).
- class (métricas por classe ou tipo de habiat).
- patch (para a mancha ou fragmento).
Primeiro, pecisamos verificar se o raster está no formato correto.
## layer crs units class n_classes OK
## 1 1 projected m integer 7 ✔Tudo certo (veja a coluna do “OK”)!
5.5.1 Métricas para a paisagem
Vamos começar avaliando a área total da paisagem (área) de estudo.
## # A tibble: 1 × 6
## layer level class id metric value
## <int> <chr> <int> <int> <chr> <dbl>
## 1 1 landscape NA NA ta 160264.Agora vamos ver a distância total de borda (te= “total edge”).
## used (Mb) gc trigger (Mb) max used (Mb)
## Ncells 8679360 463.6 19594787 1046.5 19594787 1046.5
## Vcells 38247531 291.9 118462564 903.8 148077084 1129.8## # A tibble: 1 × 6
## layer level class id metric value
## <int> <chr> <int> <int> <chr> <dbl>
## 1 1 landscape NA NA te 547140.Total de borda mede a configuração da paisagem porque uma paisagem altamente fragmentada terá muitas bordas. No entanto, a borda total é uma medida absoluta, dificultando comparações entre paisagens com
áreas totais diferentes. Mas pode ser aplicado para comparar a configuração na mesma paisagem em anos diferentes.
Agora vamos ver a densidade de Borda (“Edge Density”). Densidade de Borda mede a configuração da paisagem porque uma paisagem altamente fragmentada terá valores mais altas. “Densidade” é uma medida adequado para comparacoes de paisagens com áreas totais diferentes.
## # A tibble: 1 × 6
## layer level class id metric value
## <int> <chr> <int> <int> <chr> <dbl>
## 1 1 landscape NA NA ed 3.415.5.2 Métricas para as classes
Area de cada classe em hectares.
## # A tibble: 7 × 6
## layer level class id metric value
## <int> <chr> <int> <int> <chr> <dbl>
## 1 1 class 3 NA ca 158582.
## 2 1 class 4 NA ca 1.70
## 3 1 class 11 NA ca 1.79
## 4 1 class 12 NA ca 548.
## 5 1 class 15 NA ca 563.
## 6 1 class 30 NA ca 526.
## 7 1 class 33 NA ca 41.4Como tem varios classes é dificil de interpretar os resultados porque os numeros (3, 4, 11…..) não tem uma referncia do mundo real. Para entender os resultados, precisamos acrescentar nomes para os valores. Ou seja incluir uma coluna de legenda com os nomes para cada classe. Para isso precisamos outro arquivo com os nomes.
Baixar a arquivo de legenda: mapbiomas_6_legend.xlsx.
Agora carregar o arquivo com o codigo a seguir.
Agora rodar de novo, com os resultados juntos com a legenda de cada classe. Nos resultados acima, os valores na coluna “class” são as mesmas que tem na coluna “aid” no objeto “class_nomes”, onde também tem os nomes . Assim, podemos repetir, mas agora incluindo os nomes para cada valor de class, com base na ligação (join) entre as colunas.
# Área de cada classe em hectares, incluindo os nomes para cada classe
lsm_c_ca(r1985) |>
left_join(class_nomes, by = c("class" = "aid"))
# Numero de fragmentos (manchas)
lsm_c_np(r1985) |>
left_join(class_nomes, by = c("class" = "aid"))
# Maior numero de manchas em classes de cobertura classificadas como
# pasto (pasture) e formação campestre (grassland).
# layer level class id metric value class_description group_description
# 1 class 3 NA np 28 Forest Formation Natural forest
# 1 class 4 NA np 2 Savanna Formation Natural forest
# 1 class 11 NA np 7 Wetlands Natural non fore
# 1 class 12 NA np 246 Grassland Natural non fore.
# 1 class 15 NA np 262 Pasture Farming
# 1 class 30 NA np 35 Mining Non vegetated
# 1 class 33 NA np 50 River,Lake and Ocean Water 5.5.3 Métricas para as manchas
Vamos calcular o tamanho de cada mancha agora.
Agora queremos saber o tamanho da maior mancha em cada class, e portanto o tamanho da maior mancha de mineração.
5.5.4 Quais métricas devo escolher?
A decisão deve ser tomada com base em uma combinação de fatores. Incluindo tais fatores como: base teórica, considerações estatísticas, relevância para o objetivo/hipótese e a escala e heterogeneidade na paisagem de estudo.
Queremos caracterizar áreas de mineração na paisagem, e aqui vamos olhar somente uma paisagem, em um momento do tempo. Então as métricas para a paisagem como todo não tem relevância.
Estamos olhando uma classe (mineração), portanto vamos incluir as métricas para classes. Alem disso, as métricas de paisagem em nível de classe são mais eficazes na definição de processos ecológicos (Tischendorf, L. Can landscape indices predict ecological processes consistently?. Landscape Ecology 16, 235–254 (2001). https://doi.org/10.1023/A:1011112719782.).
5.5.5 Métricas por classe de mineração
Aqui vamos calcular todos as métricas por classe (função calculate_lsm())).
# métricas de composição para a paisagem por classes
metrics_comp <- calculate_lsm(r1985, level = "class", type = "area and edge metric")
# métricas de configuração para a paisagem por classes
metrics_config <- calculate_lsm(r1985, level = "class", type = "aggregation metric")E aqui, calcular correlações entre todos as métricas por classe (função show_correlation())).
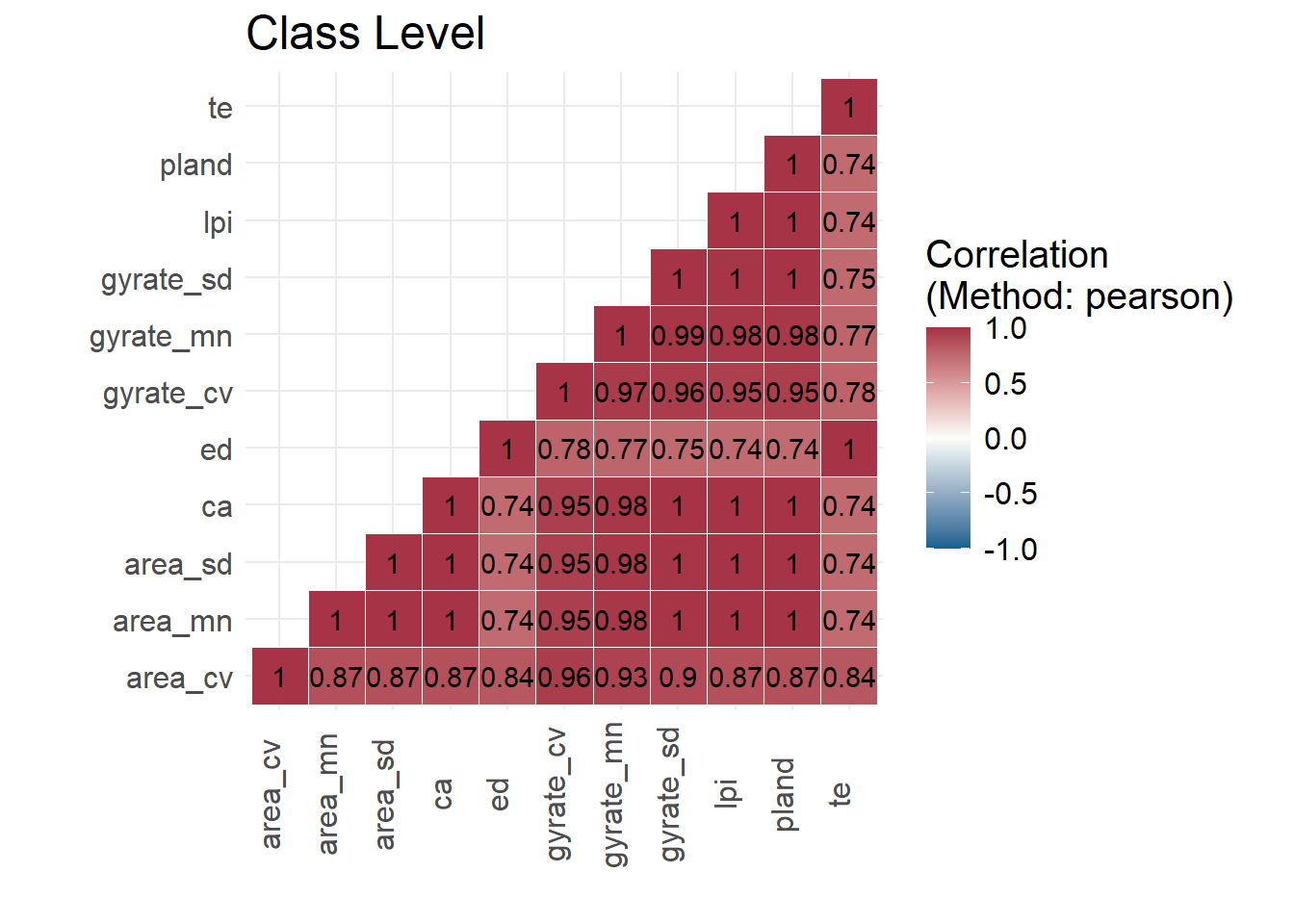
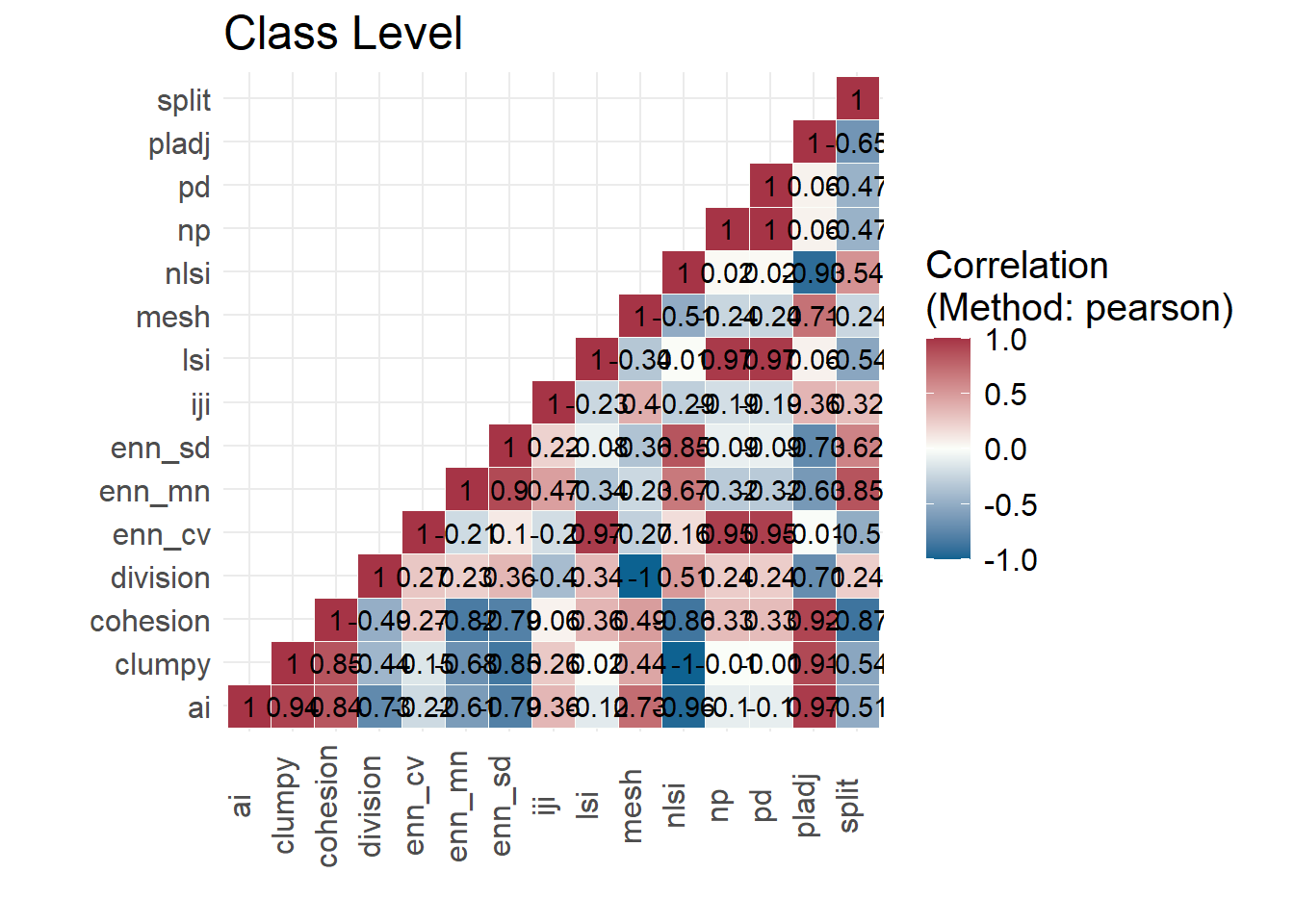
Temos muitos valores e muitas métricas. Este se chama um “tiro no escuro”, algo cujo resultado se desconhece ou é imprevisível. Isso não é recomendado. Para fazer uma escolha melhor (mais robusta), seguindo princípios básicos da ciência, precisamos ler os estudos anteriores (artigos) para obter as métricas mais relevantes para nosso objetivo e a hipótese a ser testada. Com base em os estudos anteriores e os objetivos vamos incluir 8 métricas nos resultados.
5.5.6 Exportar as métricas
O próximo passo é comunicar os resultados obtidos. Para isso precisamos resumir e apresentar as métricas selecionadas em tabelas e figuras. Agora já fizemos os cálculos, as tabelas e figuras podem ser feitas no R (figuras), tanto quanto em aplicativos diferentes (por exemplo tabelas atraves [“tabelas dinamicas”] no Microsoft Excel ou LibreOffice calc). Mas por isso, primeiramente precisamos exportar os resultados (veja mais exemplos aqui: Introdução ao R import-export.
O arquivo vai sai no mesmo diretório do seu código (verifique com getwd()).
5.6 Apresentando os resultados
5.6.1 Preparando os resultados
A entrada de dados seria com as métricas da paisagem calculados anteriormente.
Vocês devem baixar o arquivo de Excel metricas_lourenco_1985.xlsx. Lembre-se, para facilitar, os dados deve ficar no mesmo diretório do seu código (verifique com getwd()).
No caso de um arquivo de Excel simples, a importação poderia ser feita através menu de “Import Dataset” na janela/panel “Environment” de Rstudio. Ou com linhas de código:
metricas_1985 <- read_excel("metricas_lourenco_1985.xlsx")
metricas_1985
# layer level class id metric value
# <dbl> <chr> <dbl> <chr> <chr> <dbl>
# 1 class 3 NA area_cv 529.
# 1 class 4 NA area_cv 22.3
# 1 class 11 NA area_cv 71.2 Ou use o função file.choose(), que faz a busca para arquivos.
## # A tibble: 182 × 6
## layer level class id metric value
## <dbl> <chr> <dbl> <chr> <chr> <dbl>
## 1 1 class 3 NA area_cv 529.
## 2 1 class 4 NA area_cv 22.3
## 3 1 class 11 NA area_cv 71.2
## 4 1 class 12 NA area_cv 169.
## 5 1 class 15 NA area_cv 175.
## 6 1 class 30 NA area_cv 276.
## 7 1 class 33 NA area_cv 74.2
## 8 1 class 3 NA area_mn 5664.
## 9 1 class 4 NA area_mn 0.848
## 10 1 class 11 NA area_mn 0.255
## # ℹ 172 more rowsOs dados são padronizados (“tidy”), mas ainda não parece adequados para apresentação em tabelas ou figuras. Temos muitos valores e muitas métricas (listadas na coluna “metric”). Com base em os estudos anteriores e os objetivos vamos incluir 8 métricas (4 de composição e 4 de configuração).
Métricas de composição:
- mean patch area (
lsm_c_area_mn) Área médio das manchas por classe. - SD patch area (
lsm_c_area_sd) Desvio padrão das áreas dos manchas por classe. - class area percentage of landscape (
lsm_c_pland) Porcentagem de área na paisagem por classe. - largest patch index (
lsm_c_lpi) Índice de maior mancha (proporção da paisagem).
Métricas de configuração:
- aggregation index (
lsm_c_ai) Índice de agregação. - patch cohesion index (
lsm_c_cohesion) Índice de coesão das manchas. - number of patches (
lsm_c_np) Número de manchas. - patch density (
lsm_c_pd) Densidade de manchas.
Escolheremos (atraves um filtro) as métricas que queremos para obter uma tabela de dados. Mantendo os dados originais, assim sendo para acresentar mais métricas nos resultados, preciso somente acrescentar mais no codigo.
# Arquivo com os nomes das classes
class_in <- "C:\\Users\\user\\Documents\\Articles\\gis_layers\\gisdata\\inst\\raster\\mapbiomas_cover_lourenco_utm\\mapbiomas_6_legend.xlsx"
class_nomes <- read_excel(class_in)
# Especificar métricas desejados
met_comp <- c("pland", "lpi", "area_mn", "area_sd")
met_conf <- c("ai", "cohesion", "np", "pd")
met_todos <- c(met_comp, met_conf)
# Escholer métricas desejados do conjunto completo
metricas_1985 |>
filter(metric %in% met_todos) |>
left_join(class_nomes, by = c("class" = "aid")) -> metricas_nomes5.6.2 Uma tabela versatil
Mas, ainda não tem uma coluna com os nomes das métricas. Portanto, solução simples é de exportar no formato de .csv e finalizar/editar no Excel / calc.
Outra opção que pode facilitar, particularmente quando pode há mudanças e revisões, é produzir a tabela no R. Aqui vamos repetir no R os passos que vocês conhecem com as ferramentas de Excel (arraste e solte, copiar-colar, filtro, tabela dinâmica).
5.6.3 Reorganização
Escolhendo as colunas desejadas (select), reorganizando para as métricas ficam nas colunas (pivot_wider) e colocando as colunas novas na sequência desejada (select).
5.6.4 Uma figura elegante
Uma imagem vale mais que mil palavras. Portanto, gráficos/figuras/imagens são uma das mais importantes formas de comunicar a ciência.
Como exemplo ilustrativo, aqui vamos produzir gráficos comparando métricas de composição e configuração da paisagem ao redor do Garimpo do Lourenço.
É uma boa ideia gastar bastante tempo para tornar figuras científicas as mais informativas e atraentes possíveis. Escusado será dizer que a precisão empírica é primordial. E por isso, o que fica excluído/omitido é tão importante quanto o que foi incluído. Para ajudar, você deve se perguntar o seguinte ao criar uma figura: eu apresentaria essa figura em uma apresentação para um grupo de colegas? Eu o apresentaria a um público de não especialistas? Eu gostaria que essa figura aparecesse em um artigo de notícias sobre meu trabalho? É claro que todos esses locais exigem diferentes graus de precisão, complexidade e estética, mas uma boa figura deve servir para educar simultaneamente públicos muito diferentes.
Tabelas versus gráficos — A primeira pergunta que você deve se fazer é se você pode transformar aquela tabela (chata e feia) em algum tipo de gráfico. Você realmente precisa dessa tabela no texto principal? Você não pode simplesmente traduzir as entradas das células em um gráfico de barras/colunas/xy? Se você pode, você deve. Quando uma tabela não pode ser facilmente traduzida em uma figura, na maioria das vezes a provavelmente pertence às Informações Suplementares/Anexos/Apêndices.
5.6.4.1 Gráfico de barra
Primeiramente, vamos produzir uma gráfico de barra comparando a proporção que cada classe representa na paisagem.
# Inclundo cores conforme legenda da Mapbiomas Coleção 6
# Legenda nomes ordem alfabetica
classe_cores <- c("Campo Alagado e Área Pantanosa" = "#45C2A5",
"Formação Campestre" = "#B8AF4F",
"Formação Florestal" = "#006400",
"Formação Savânica" = "#00ff00",
"Mineração" = "#af2a2a",
"Pastagem" = "#FFD966",
"Rio, Lago e Oceano" = "#0000FF") E agora o grafico…….
# Grafico de barra basica
metricas_tab |>
mutate(class_prop = pland) |>
ggplot(aes(x = classe_descricao, y = class_prop)) +
geom_col()
# Agora com ajustes
# Agrupando por tipo (natural e antropico)
# Com cores conforme legenda da Mapbiomas Coleção 6
# Corrigindo texto dos eixos.
# Mudar posição da leganda para o texto com nomes longas encaixar.
metricas_tab |>
mutate(class_prop = pland) |>
ggplot(aes(x = type_class, y = class_prop,
fill = classe_descricao)) +
scale_fill_manual("classe", values = classe_cores) +
geom_col(position = position_dodge2(width = 1)) +
coord_flip() +
labs(title = "MapBiomas cobertura da terra",
subtitle = "Entorno do Garimpo do Lorenço 1985",
y = "Proporção da paisagem (%)",
x = "") +
theme(legend.position="bottom") +
guides(fill = guide_legend(nrow = 4))Uma imagem vale mais que mil palavras:
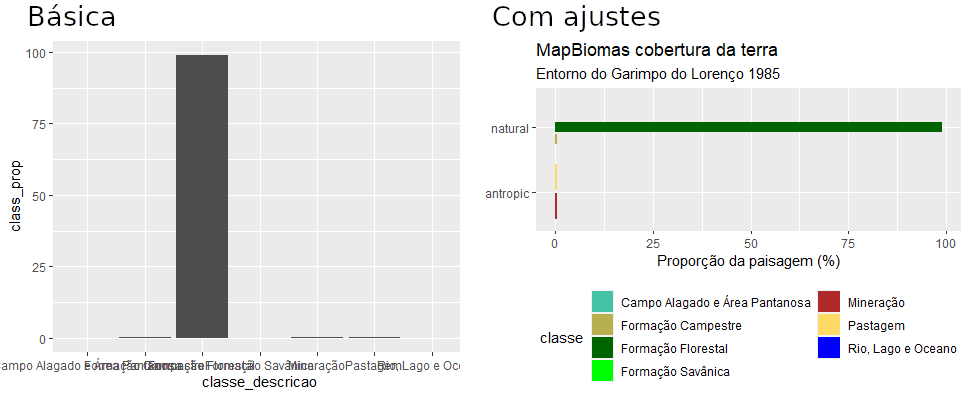
Mas existe uma separação grande na faixa de valores e ainda é difícil de ver todas as classes. Temos uma distribuição com valores muito mais altos comparada com os outros. extremos. Uma solução seria uma transformação (por exemplo “log”), assim os valores ficarem mais proximos.
5.6.4.2 Gráfico de boxplot
Agora com uma métrica de configuração:
# Métrica de configuração: Densidade de manchas (coluna "pd").
# Agrupando por tipo (natural e antrópico)
# Incluindo boxplot indicando tendência central (mediano)
# Com cores conforme legenda da Mapbiomas Coleção 6
# Tamanho dos pontos proporcional o numero de manchas
# Corrigindo texto dos eixos.
# Mudar posição da leganda para o texto com nomes longas encaixar.
metricas_tab |>
ggplot(aes(x = type_class, y = pd)) +
geom_boxplot(colour = "grey50") +
geom_point(aes(size = np, colour = classe_descricao)) +
scale_color_manual("classe", values = classe_cores) +
scale_size(guide = "none") +
coord_flip() +
labs(title = "MapBiomas cobertura da terra",
subtitle = "Entorno do Garimpo do Lorenço 1985",
y = "Densidade de manchas (número por 100 hectares)",
x = "") +
theme(legend.position="bottom") +
guides(col = guide_legend(nrow = 4)) 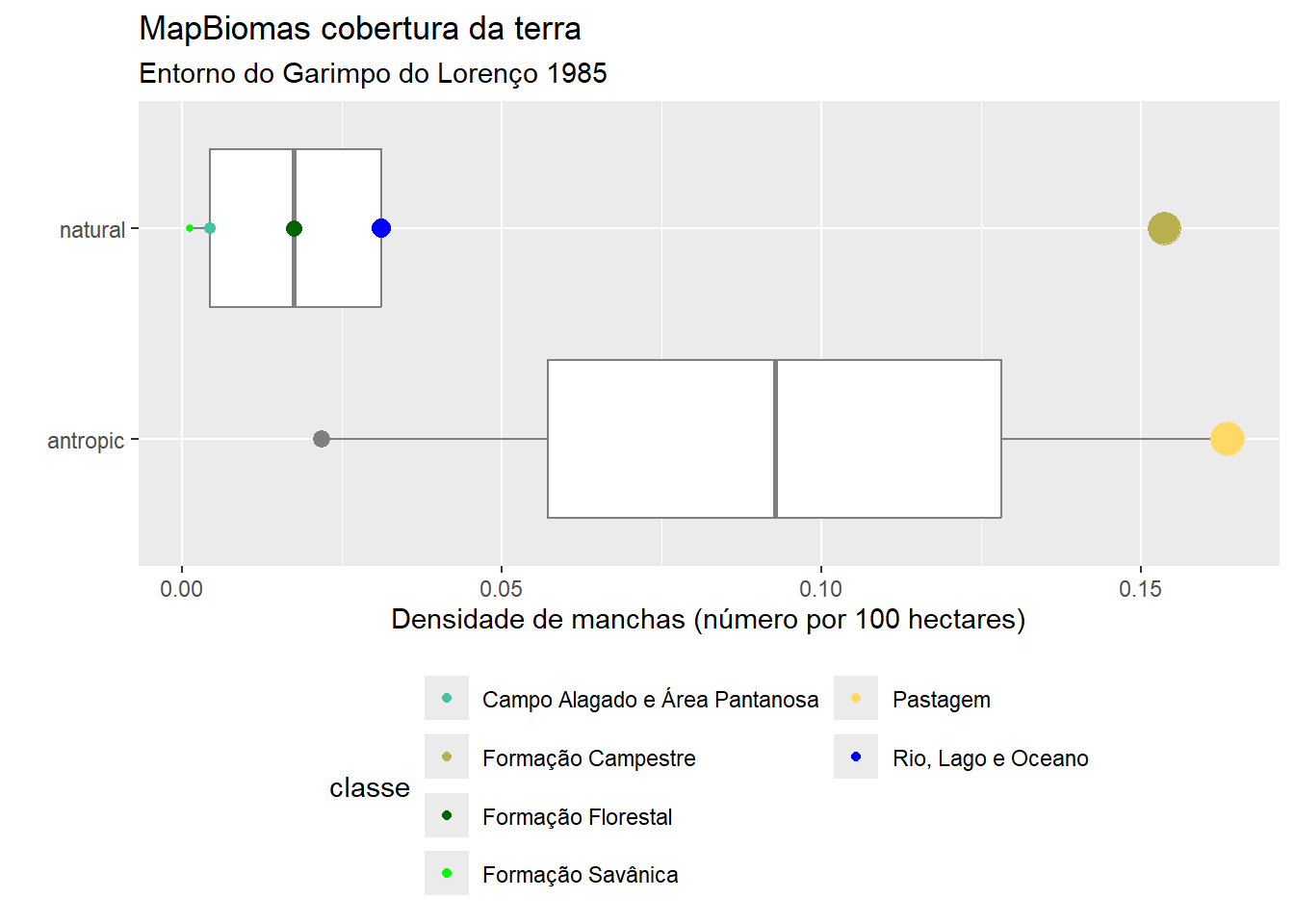
5.7 Comparação entre anos
Calcular as métricas para 3 anos.
# metricas desejados
what_metricas <- c("lsm_c_pland", "lsm_c_lpi", "lsm_c_area_mn", "lsm_c_area_sd",
"lsm_c_ai", "lsm_c_cohesion", "lsm_c_np", "lsm_c_pd")
# rodar
metricas_anos <- sample_lsm(landscape = mapbiomas_85a20,
y = acesso_buffers,
plot_id = data.frame(acesso_buffers)[, 'raio_km'],
what = what_metricas,
edge_depth = 1)
# Organizar dados
# Dados rferentes os buffers
resultados_anos <- acesso_buffers |>
left_join(metricas_anos |>
dplyr::mutate(value = round(value,2),
ano = case_when(layer==1 ~1985,
layer==2~2003,
layer==3~2020)) |>
dplyr::select(ano, plot_id, class, metric, value),
by=c("raio_km"="plot_id"))
# Dados referentes os classes
resultados_anos <- resultados_anos |>
left_join(class_nomes, by = c("class" = "aid"))Agora grafico de barra com varios anos
# It's recommended to use a named vector
# Legenda nomes ordem alfabetica
classe_cores <- c("Campo Alagado e Área Pantanosa" = "#45C2A5",
"Formação Campestre" = "#B8AF4F",
"Formação Florestal" = "#006400",
"Formação Savânica" = "#00ff00",
"Mineração" = "#af2a2a",
"Pastagem" = "#FFD966",
"Rio, Lago e Oceano" = "#0000FF",
"Outras Lavouras Temporárias" = "#e787f8")
resultados_anos |>
mutate(rcor = paste("#", hexadecimal_code, sep="")) |>
filter(metric=="pland") |>
ggplot(aes(x=ano, y=value)) +
geom_col(position="stack", aes(fill=classe_descricao)) +
scale_fill_manual(values = classe_cores) +
facet_grid(raio_km~type_class)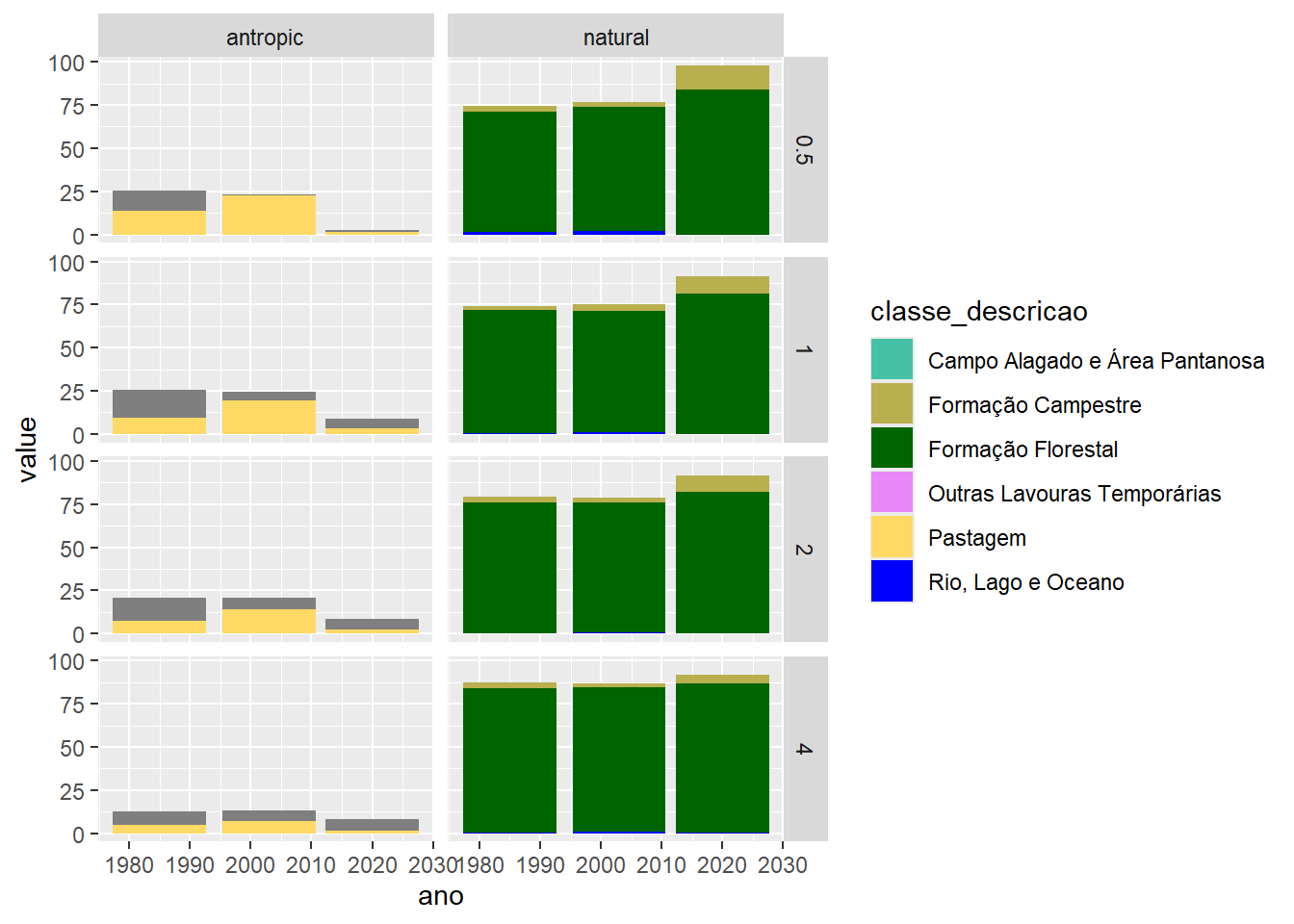
Agora com “pland” e densidade de manchas juntos.
resultados_anos |>
mutate(rcor = paste("#", hexadecimal_code, sep="")) |>
filter(metric=="pland") |>
ggplot(aes(x=ano, y=value)) +
geom_col(position="stack", aes(fill=classe_descricao)) +
scale_fill_manual("classe", values = classe_cores) +
scale_y_continuous(breaks=c(0,50,100)) +
scale_x_continuous(breaks=c(1985,2003, 2020)) +
facet_grid(raio_km~type_class) +
labs(title = "MapBiomas cobertura da terra",
subtitle = "Entorno do Garimpo do Lorenço 1985-2020",
y = "Porcentagem da paisagem",
x = "Ano") +
theme(legend.position="bottom",
legend.title = element_text(size = 3),
legend.text = element_text(size = 3),
legend.key.size = unit(0.1, "lines")) +
guides(fill = guide_legend(nrow = 4)) -> fig_pland
# Densidade de manchas
resultados_anos |>
mutate(rcor = paste("#", hexadecimal_code, sep="")) |>
filter(metric=="pd") |>
ggplot(aes(x = factor(ano), y = value)) +
geom_boxplot(colour = "grey50") +
geom_point(aes(colour = classe_descricao)) +
scale_color_manual("classe", values = classe_cores) +
scale_size(guide = "none") +
facet_grid(raio_km~type_class) +
labs(title = "MapBiomas cobertura da terra",
subtitle = "Entorno do Garimpo do Lorenço 1985-2020",
y = "Densidade de manchas (número por 100 hectares)",
x = "Ano") +
theme(legend.position="bottom",
legend.title = element_text(size = 3),
legend.text = element_text(size = 3),
legend.key.size = unit(0.1, "lines")) +
guides(fill = guide_legend(nrow = 4)) -> fig_pd
grid.arrange(fig_pland, fig_pd, nrow=1)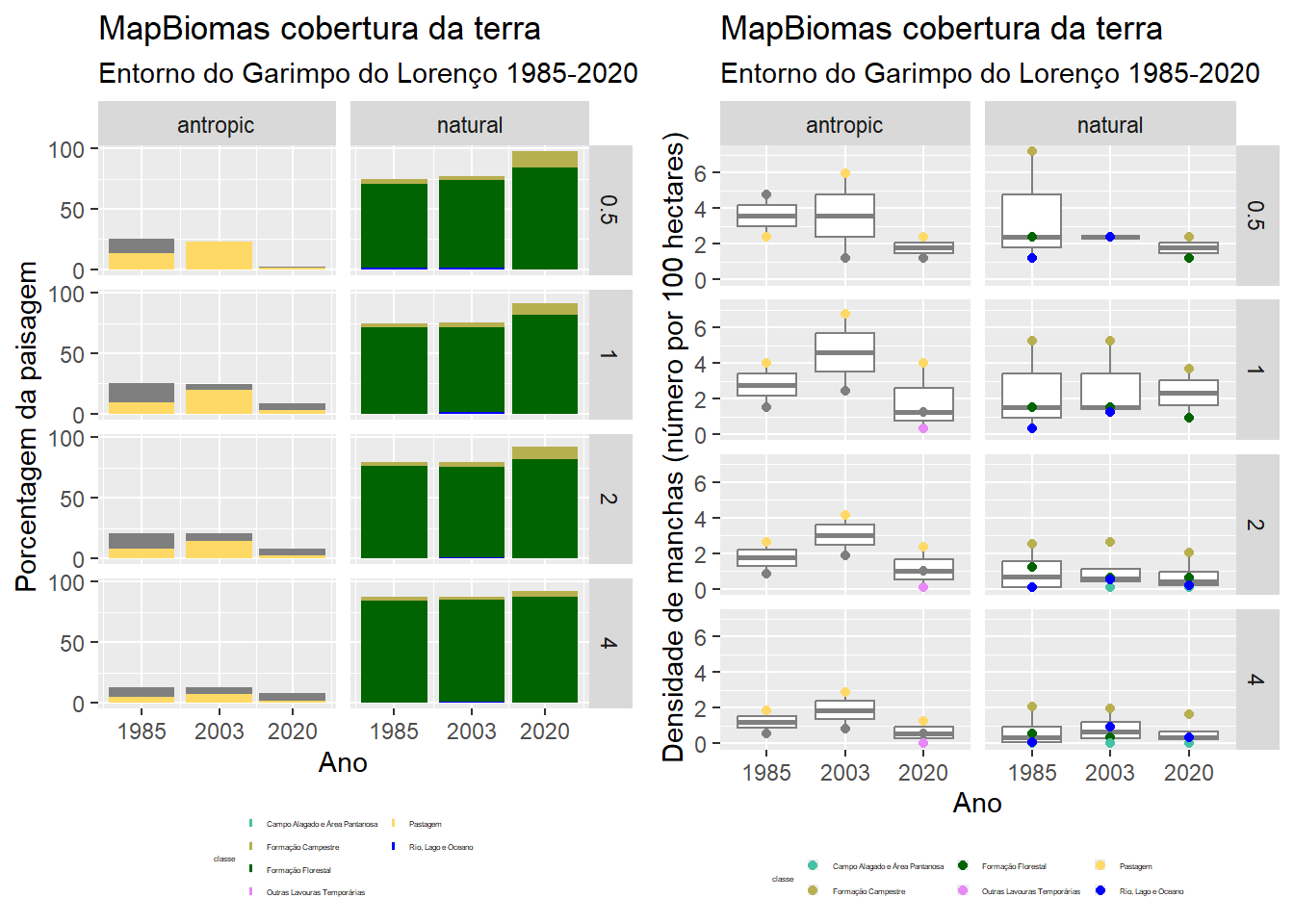
5.8 Comparação entre anos e paisagens
Aqui compararemos as mudanças na cobertura e uso da terra entre dois garimpos: Garimpo do Lourenço e Garimpo do Vila Nova. Como eles estão separados por aproximadamente 200 quilômetros em linha reta, iremos processar os dois separadamente e depois combinar os resultados.
5.8.1 Dados: anos
Para Vila Nova, vamos incluir buffers com os mesmos raios do que fizemos para Garimpo do Lourenço.
5.8.1.1 Dados vetor: anos
# Tabela de dados com coordenados.
acesso_vn <- data.frame(nome = "garimpo do Vila Nova",
coord_x = -51.735512,
coord_y = 0.402381)
# Converter para objeto espacial, com sistema de coordenados geográfica.
sf_acesso_vn <- st_as_sf(acesso_vn,
coords = c("coord_x", "coord_y"),
crs = 4326)
# Agora fazer os buffers
# Reprojetar o ponto.
sf_acesso_vn_utm <- st_transform(sf_acesso_vn, crs = 31976)
# Polígono com raio de 500 metros no entorno do ponto.
sf_acesso_vn_500m <- st_buffer(sf_acesso_vn_utm, dist=500) |>
mutate(raio_km = 0.5)
# Polígono com raio de 1 km no entorno do ponto.
sf_acesso_vn_1km <- st_buffer(sf_acesso_vn_utm, dist=1000) |>
mutate(raio_km = 1)
# Polígono com raio de 2 km no entorno do ponto.
sf_acesso_vn_2km <- st_buffer(sf_acesso_vn_utm, dist=2000) |>
mutate(raio_km = 2)
# Polígono com raio de 4 km no entorno do ponto.
sf_acesso_vn_4km <- st_buffer(sf_acesso_vn_utm, dist=4000) |>
mutate(raio_km = 4)
# Polígono com raio de 20 km no entorno do ponto.
sf_acesso_vn_20km <- st_buffer(sf_acesso_vn_utm,
dist=20000) |>
mutate(raio_km = 20)
acesso_buffers_vn <- bind_rows(sf_acesso_vn_500m,
sf_acesso_vn_1km,
sf_acesso_vn_2km,
sf_acesso_vn_4km)Verificar:
5.8.2 Mapa.
Primeiro queremos comparar visualmente as mudanças na cobertura da terra ao longo do tempo. Para fazer isso, precisamos saber a que correspondem os valores de classificação numérica nos rasters no mundo real. Para entender o que os valores (3, 12, 33 … etc) representam no mundo real precisamos de uma referência (legenda). Para a MapBiomas Coleção 8, baixar o arquivo: https://brasil.mapbiomas.org/wp-content/uploads/sites/4/2023/09/Codigos-da-legenda-colecao-8-csv.zip . Lembre-se de descompactar e salvar em um local conhecido no seu computador.
Carregar a legenda do Mapbiomas.
# Mapbiomas legend
legendfile <- "data/raster/mapbiomas/legend/Codigos-da-legenda-colecao-8.csv"
# Carregar a legenda e encurte alguns nomes de classes muito longos
mapbiomas_legend <- read.csv2(file.choose(), as.is = TRUE) |>
mutate(Descricao_novo = case_when(Descricao == "Campo Alagado e Área Pantanosa" ~ "Campo Alagado",
Descricao == "Outras Lavouras Temporárias" ~ "Outras Lavouras")) |>
mutate(Descricao = coalesce(Descricao_novo, Descricao))
# Nova coluna para identificar classes antroopicos:
antropico <- c("Agropecuária", "Pastagem", "Agricultura",
"Lavoura Temporária", "Soja", "Cana",
"Arroz", "Algodão (beta)", "Outras Lavouras" ,
"Lavoura Perene", "Café", "Citrus", "Dendê (beta)",
"Outras Lavouras Perenes", "Silvicultura", "Mosaico de Usos",
"Área Urbanizada", "Mineração", "Aquicultura")
mapbiomas_legend$tipo <- ifelse(mapbiomas_legend$Descricao %in% antropico,
"antropico", "natural")5.8.2.1 Mapa: Lourenço
Aqui usamos a modal de três anos para suavizar a variação nas estimativas de dados anuais da classificação de cobertura terrestre do MapBiomas. Para os três anos usamos:
- o ano atual,
- o ano anterior e
- o ano seguinte.
Obter o valor modal de três anos para suavizar a variação na classificação (mais detalhes no Capítulo 3):
Selecionar os três anos com
subset(),Aggregar pixels para reduzir tempo de processamento
aggregate()eCalcular o valor modal de cada pixel para os três anos
modal().
# 85 a 87
r86 <- subset(r85a22_l, c(2, 1, 3))
r86_agg10 <- aggregate(r86, fact=5, fun="modal")
r86_agg10_mod <- modal(r86_agg10, ties = "first")
names(r86_agg10_mod) <- "modal_85a87"
# 2020 a 2022
r21 <- subset(r85a22_l, c(37, 38, 36))
r21_agg10 <- aggregate(r21, fact=5, fun="modal")
r21_agg10_mod <- modal(r21_agg10, ties = "first")
names(r21_agg10_mod) <- "modal_20a22"
r86a21 <- c(r86_agg10_mod, r21_agg10_mod)Fazer legenda para rasters de 86 e 21.
classes_r86a21 <- sort(unique(c(as.numeric(unlist(unique(r86_agg10_mod))),
as.numeric(unlist(unique(r21_agg10_mod)))
)))
classes_l <- mapbiomas_legend |>
filter(Class_ID %in% classes_r86a21) |>
arrange(Class_ID)
mybreaks <- as.character(classes_r86a21)Agora fazer a mapa.
fig_mapa_lourenco <- ggplot() +
geom_spatraster(data = as.factor(r86a21)) +
geom_sf(data = sf_acesso_4km,
fill = "transparent",
linetype = "longdash",
colour = "white", size = 0.7) +
scale_fill_manual("Classe", breaks= mybreaks,
labels= classes_l$Descricao,
values = classes_l$Color) +
scale_x_continuous(breaks =
c(-51.8, -51.7, -51.6, -51.5)) +
facet_wrap(~lyr, ncol = 2) +
theme(legend.position = "top")
fig_mapa_lourenco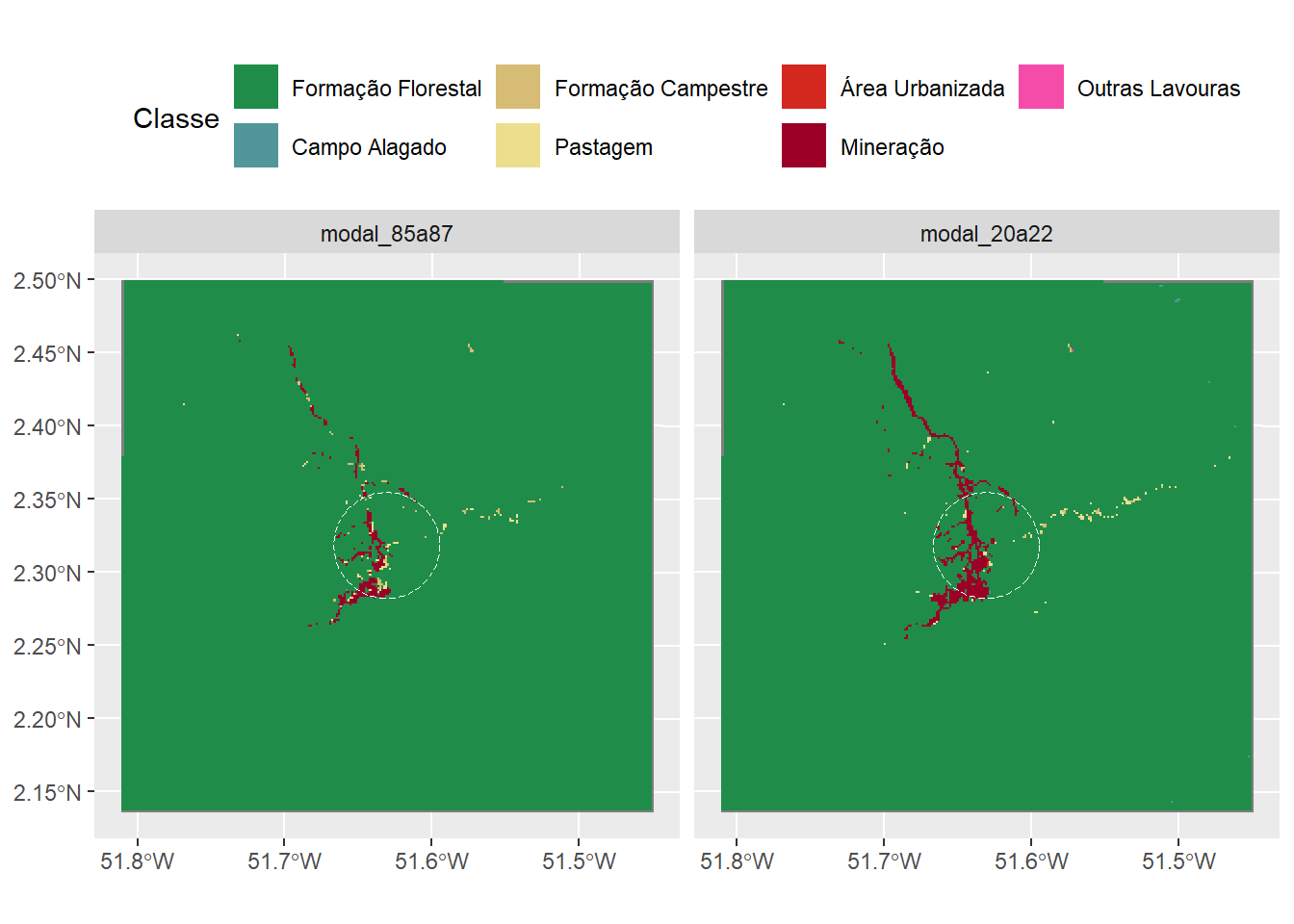
Salvar.
5.8.2.2 Mapa: Vila Nova
# 85 a 87
r86 <- subset(r85a22_vn, c(2, 1, 3))
r86_agg10 <- aggregate(r86, fact=5, fun="modal")
r86_agg10_mod <- modal(r86_agg10, ties = "first")
names(r86_agg10_mod) <- "modal_85a87"
# 2020 a 2022
r21 <- subset(r85a22_vn, c(37, 38, 36))
r21_agg10 <- aggregate(r21, fact=5, fun="modal")
r21_agg10_mod <- modal(r21_agg10, ties = "first")
names(r21_agg10_mod) <- "modal_20a22"
r86a21 <- c(r86_agg10_mod, r21_agg10_mod)Fazer legenda para rasters de 86 e 21.
classes_r86a21 <- sort(unique(c(as.numeric(unlist(unique(r86_agg10_mod))),
as.numeric(unlist(unique(r21_agg10_mod)))
)))
classes_vn <- mapbiomas_legend |>
filter(Class_ID %in% classes_r86a21) |>
arrange(Class_ID)
mybreaks_vn <- as.character(classes_r86a21)Agora fazer a mapa.
fig_mapa_vilanova <- ggplot() +
geom_spatraster(data = as.factor(r86a21)) +
geom_sf(data = sf_acesso_vn_4km,
fill = "transparent",
linetype = "longdash",
colour = "white", size = 0.7) +
scale_fill_manual("Classe", breaks= mybreaks_vn,
labels= classes_vn$Descricao,
values = classes_vn$Color) +
scale_x_continuous(breaks =
c(-51.9, -51.8, -51.7, -51.6)) +
facet_wrap(~lyr, ncol = 2) +
theme(legend.position = "top")
fig_mapa_vilanova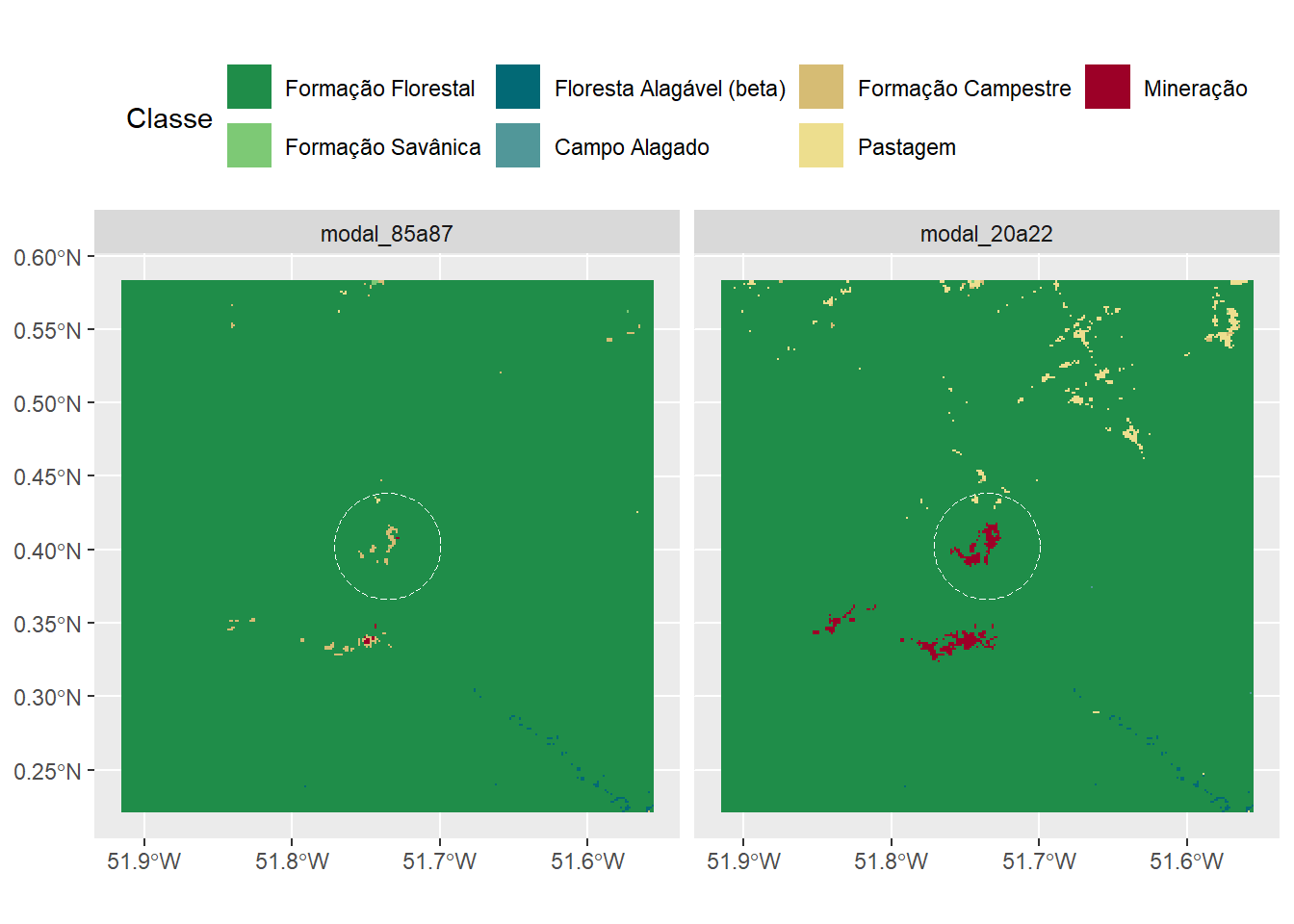
Salvar.
5.8.3 Métricas
5.8.3.1 Métricas: Diversidade da paisagem
A expectativa é que se houvesse mudanças na paisagem (por exemplo, novas classes que poderiam incluir usos humanos, como mineração e áreas urbanas), então métricas como a diversidade da paisagem deveriam aumentar significativamente.
Tome cuidado, pois se for executado em grandes paisagens, isso pode levar algum tempo (horas). Para este exemplo, primeiro cortamos o raster para uma extensão menor de quatro quilômetros usando o buffer que fizemos anteriormente.
# Cortar
r85a22_l_c <- crop(r85a22_l, sf_acesso_4km, snap="out")
r85a22_vn_c <- crop(r85a22_vn, sf_acesso_vn_4km, snap="out")
# Métricas
# lsm_l_joinent = Complexity of a landscape pattern.
# An overall spatio-thematic complexity metric.
# lsm_l_ent = diversity
# (thematic complexity) of landscape classes.
# lsm_l_condent = geometric intricacy
# (configurational complexity) of a landscape pattern.
# lsm_l_shdi = Shannon diversity
mymetrics <- c("lsm_l_joinent", "lsm_l_ent",
"lsm_l_condent", "lsm_l_shdi")
# Métricas para toda a paisagem de 4 quilometros
# acerca do Garimpo do Lourenço.
# Lourenço
metricas_lourenco <- calculate_lsm(r85a22_l_c,
what = mymetrics)
# Vila Nova
metricas_vilanova <- calculate_lsm(r85a22_vn_c,
what = mymetrics)Acabamos de calcular quatro métricas de paisagem diferentes ao longo de 38 anos. Assim sendo, os resultados (no novo objeto metricas_lourenco) deve ter 152 linhas (4 métricas X 38 anos = 152).
Aora vamos arrumar os dados para facilitar apresentação e comunicação dos resultados:
resultados_anos_lourenco <- metricas_lourenco |>
dplyr::mutate(value = round(value,2),
onde = "Garimpo do Lourenço",
ano = case_when(layer==1~1985,
layer==2~1986,
layer==3~1987,
layer==4~1988,
layer==5~1989,
layer==6~1990,
layer==7~1991,
layer==8~1992,
layer==9~1993,
layer==10~1994,
layer==11~1995,
layer==12~1996,
layer == 13 ~ 1997,
layer == 14 ~ 1998,
layer == 15 ~ 1999,
layer == 16 ~ 2000,
layer == 17 ~ 2001,
layer == 18 ~ 2002,
layer == 19 ~ 2003,
layer == 20 ~ 2004,
layer == 21 ~ 2005,
layer == 22 ~ 2006,
layer == 23 ~ 2007,
layer == 24 ~ 2008,
layer == 25 ~ 2009,
layer == 26 ~ 2010,
layer == 27 ~ 2011,
layer == 28 ~ 2012,
layer == 29 ~ 2013,
layer == 30 ~ 2014,
layer == 31 ~ 2015,
layer == 32 ~ 2016,
layer == 33 ~ 2017,
layer == 34 ~ 2018,
layer == 35 ~ 2019,
layer == 36 ~ 2020,
layer == 37 ~ 2021,
layer == 38 ~ 2022))E agora para Vila Nova.
resultados_anos_vilanova <- metricas_vilanova |>
dplyr::mutate(value = round(value,2),
onde = "Garimpo do Vila Nova",
ano = case_when(
layer==1 ~ 1985,
layer==2 ~ 1986,
layer==3 ~ 1987,
layer==4 ~ 1988,
layer==5 ~ 1989,
layer==6 ~ 1990,
layer==7 ~ 1991,
layer==8 ~ 1992,
layer==9 ~ 1993,
layer==10 ~ 1994,
layer==11 ~ 1995,
layer==12 ~ 1996,
layer == 13 ~ 1997,
layer == 14 ~ 1998,
layer == 15 ~ 1999,
layer == 16 ~ 2000,
layer == 17 ~ 2001,
layer == 18 ~ 2002,
layer == 19 ~ 2003,
layer == 20 ~ 2004,
layer == 21 ~ 2005,
layer == 22 ~ 2006,
layer == 23 ~ 2007,
layer == 24 ~ 2008,
layer == 25 ~ 2009,
layer == 26 ~ 2010,
layer == 27 ~ 2011,
layer == 28 ~ 2012,
layer == 29 ~ 2013,
layer == 30 ~ 2014,
layer == 31 ~ 2015,
layer == 32 ~ 2016,
layer == 33 ~ 2017,
layer == 34 ~ 2018,
layer == 35 ~ 2019,
layer == 36 ~ 2020,
layer == 37 ~ 2021,
layer == 38 ~ 2022
)
)Apresentar os resultados em um gráfico.
## `geom_smooth()` using formula = 'y ~ s(x, bs = "cs")'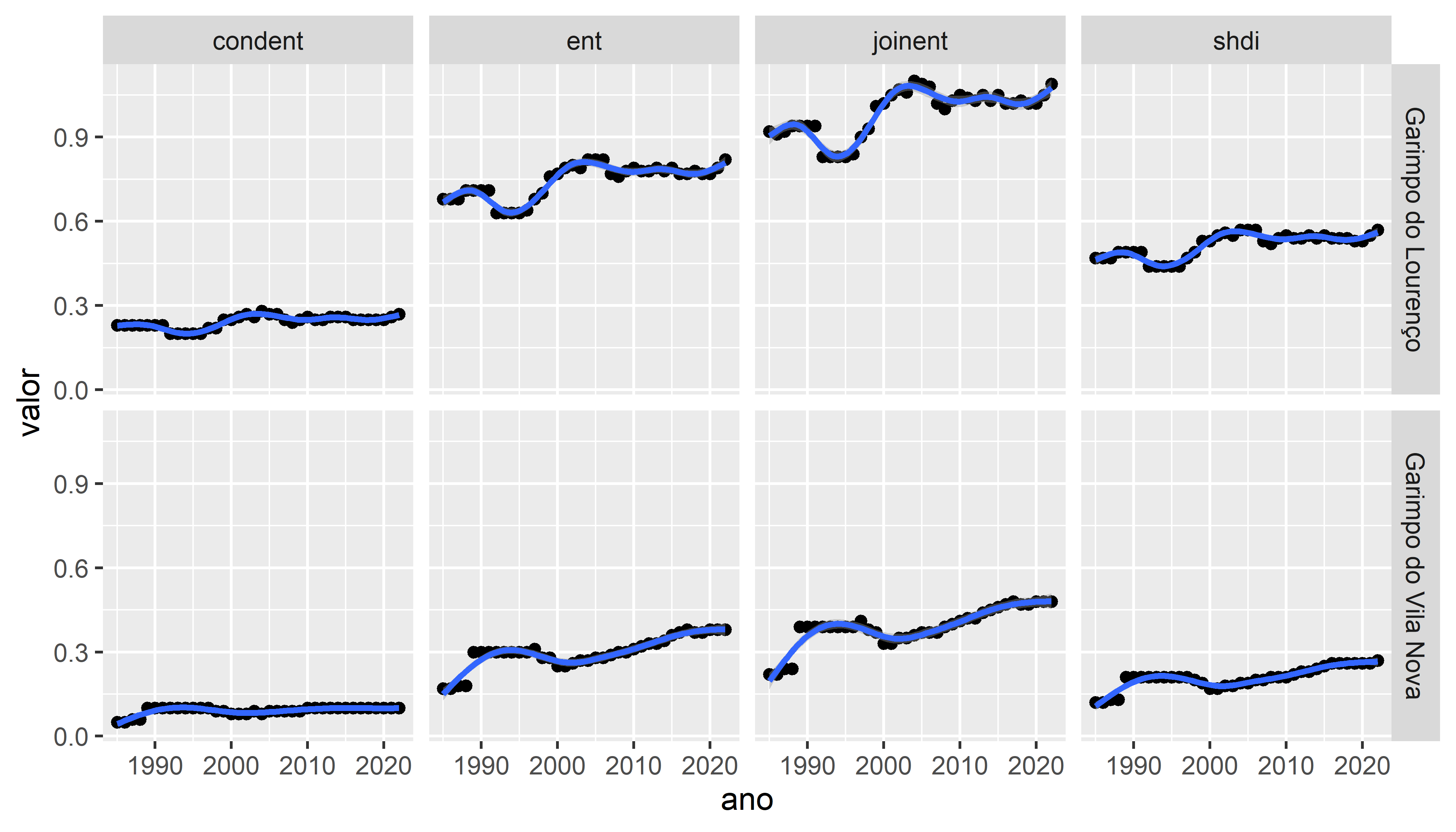
Figura 5.1: Comparação da diversidade da paisagem em torno de dois garimpos. CComparação de mudanças dentro de quatro quilômetros de Garimpo do Lourenço e garimpo do Vila Nova entre 1985 a 2022. Classificação de cobertura da terra do MapBiomas Coleção 8 usada para quantificar a diversidade representado por quatro métricas de paisagem (condent: Entropia condicional; ent: Entropia marginal; joinent: Entropia conjunta; shdi: Índice de diversidade de Shannon).
Esses resultados mostram mudanças na diversidade da paisagem ao longo do tempo que diferem entre os garimpos. Como podemos ver que os valores de diversidade diferem (Lourenço tende a ter maior diversidade desde o início) seria útil comparar a dinâmica calculada como taxas de mudanças ao longo do tempo. Além disso, agora que sabemos que houve mudanças, faz sentido investigar mais a fundo. Para compreender as mudanças, é necessária uma análise mais aprofundada que compare as métricas de nível de classe em diferentes escalas. Isto permitir-nos-á compreender exactamente que tipos de cobertura do solo mudaram e como essas mudanças estão relacionadas com a mineração e outros usos, como o desenvolvimento urbano.
Poderia ser mais informativo combinar os mapas com os gráficos para que possamos ver padrões espaciais e temporais ao mesmo tempo.
diversidade_lourenco <- ggplot(resultados_anos_lourenco,
aes(x = ano, y = value)) +
geom_point() +
stat_smooth(method = "gam") +
facet_wrap( ~ metric, ncol = 4) +
labs(y = "valor")
fig_combo_lourenco <- fig_mapa_lourenco / diversidade_lourenco +
plot_annotation(tag_levels = 'A',
tag_prefix = '(', tag_suffix = ')')
fig_combo_lourenco## `geom_smooth()` using formula = 'y ~ s(x, bs = "cs")'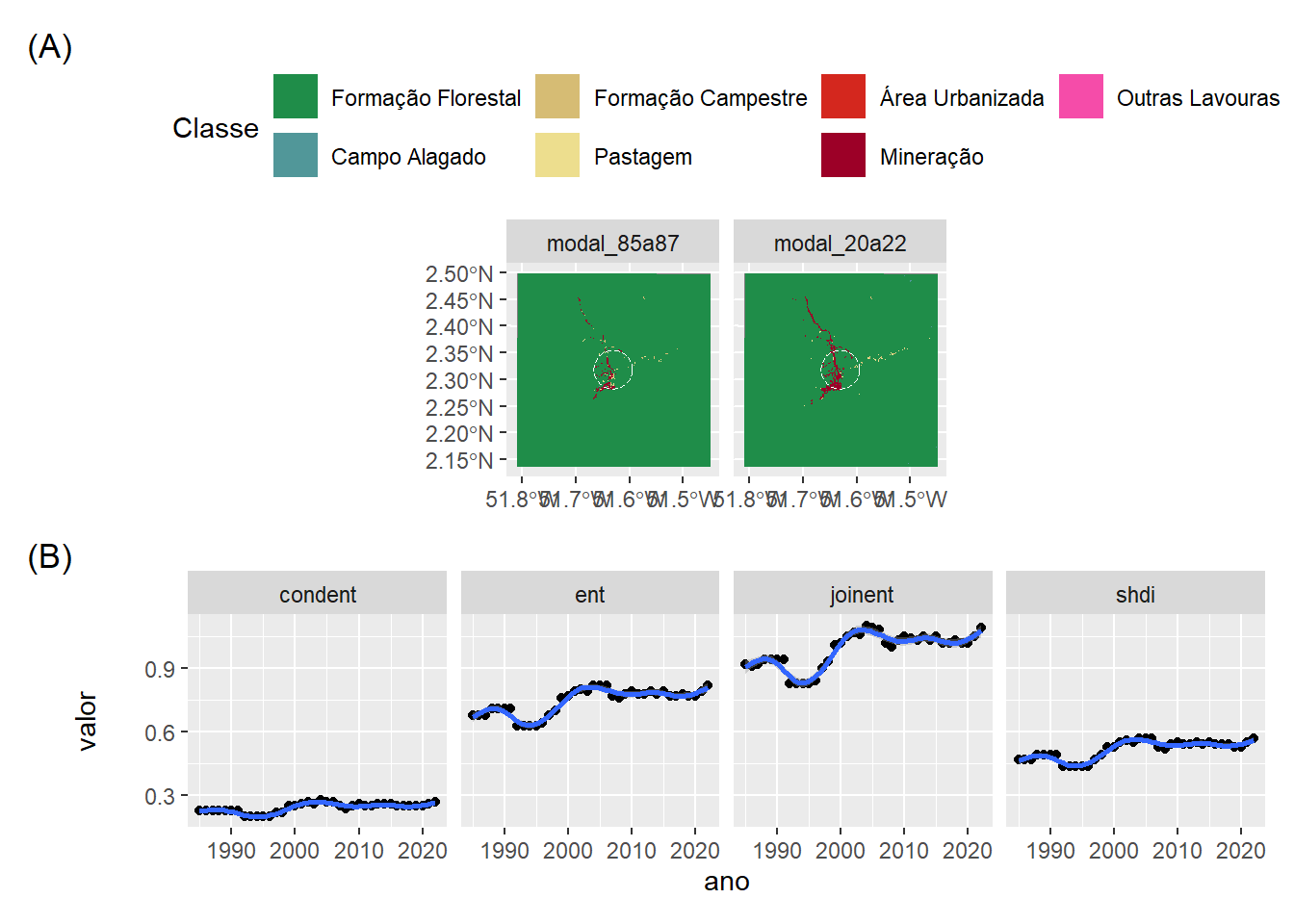
Para obter uma imagem mais clara podemos especificar as proporções relativas (comprimento e largura) e exportar. Exportar.
5.8.4 Comparar classes
Podemos comparar entre as diferentes classes para compreender como o uso antropogénico da terra mudou ao longo do tempo.
minha_metricas <- c("lsm_c_cpland")
lourenco_cpland <- sample_lsm(r85a22_l, acesso_buffers,
what = minha_metricas,
plot_id = data.frame(acesso_buffers)[, 'raio_km'])Arrumar os dados e compare a proporção de floresta e mineração ao longo do tempo.
lourenco_cpland_anos <- lourenco_cpland |>
dplyr::mutate(value = round(value,2),
onde = "Garimpo do Lourenço",
ano = case_when(layer==1~1985,
layer==2~1986,
layer==3~1987,
layer==4~1988,
layer==5~1989,
layer==6~1990,
layer==7~1991,
layer==8~1992,
layer==9~1993,
layer==10~1994,
layer==11~1995,
layer==12~1996,
layer == 13 ~ 1997,
layer == 14 ~ 1998,
layer == 15 ~ 1999,
layer == 16 ~ 2000,
layer == 17 ~ 2001,
layer == 18 ~ 2002,
layer == 19 ~ 2003,
layer == 20 ~ 2004,
layer == 21 ~ 2005,
layer == 22 ~ 2006,
layer == 23 ~ 2007,
layer == 24 ~ 2008,
layer == 25 ~ 2009,
layer == 26 ~ 2010,
layer == 27 ~ 2011,
layer == 28 ~ 2012,
layer == 29 ~ 2013,
layer == 30 ~ 2014,
layer == 31 ~ 2015,
layer == 32 ~ 2016,
layer == 33 ~ 2017,
layer == 34 ~ 2018,
layer == 35 ~ 2019,
layer == 36 ~ 2020,
layer == 37 ~ 2021,
layer == 38 ~ 2022))Gráfico:
lourenco_cpland_anos |>
left_join(mapbiomas_legend, by = c('class'='Class_ID')) |>
rename("raio" = "plot_id") |>
filter(Descricao %in% c("Formação Florestal", "Mineração")) |>
ggplot(aes(x = ano, y = value)) +
geom_point() +
scale_color_discrete("raio (km)") +
stat_smooth(method = "gam",
aes(colour = factor(raio))) +
facet_grid(raio ~ Descricao) ## `geom_smooth()` using formula = 'y ~ s(x, bs = "cs")'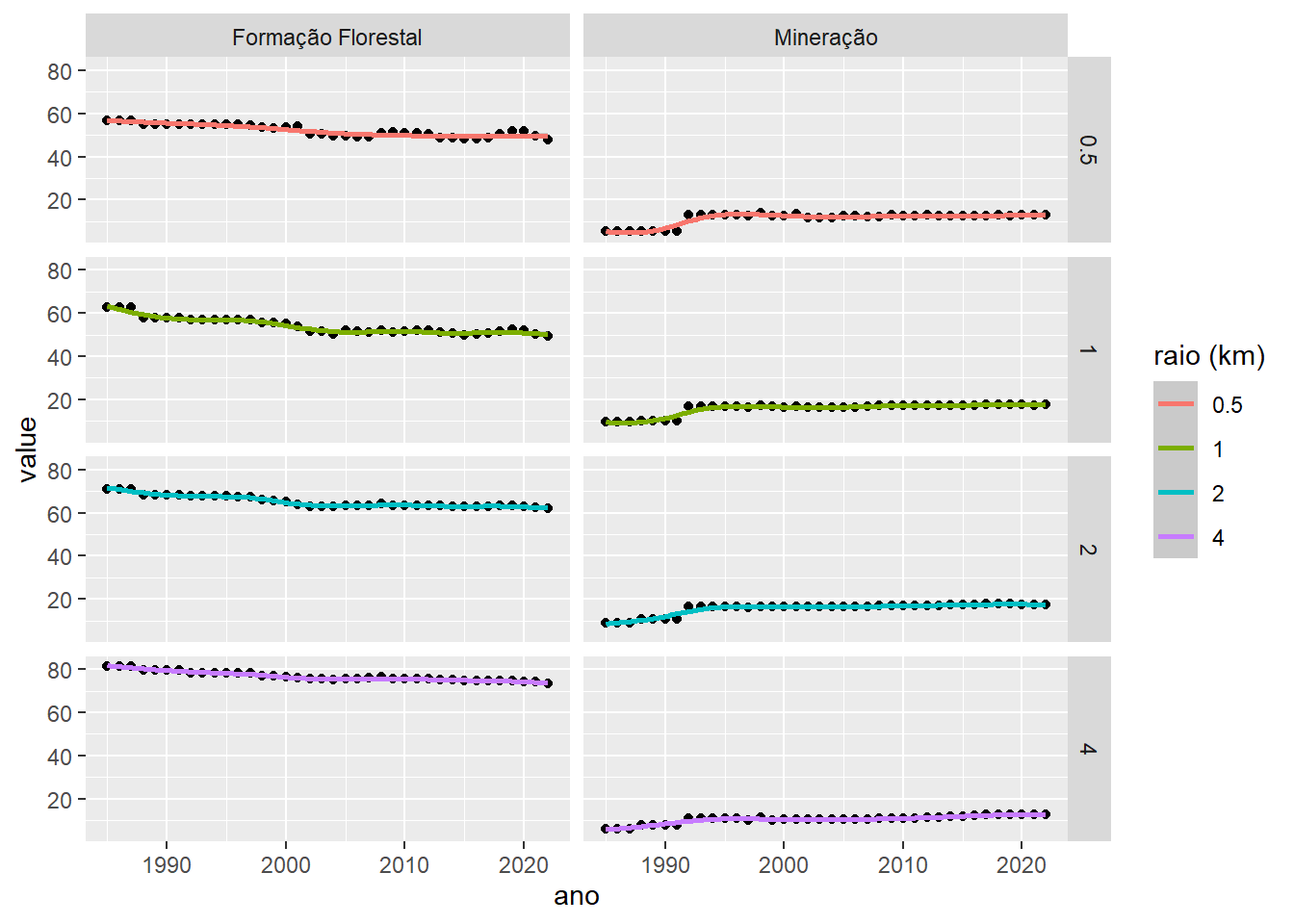
5.9 Conclusões e próximos passos
Para entender melhor os padores, precisamos:
- Verficar padrões nas outras metricas calculados
- Verficar padrões usando poligonos/pontos dos processos de mineração (dados no SIGMINE https://www.gov.br/anm/pt-br e https://app.anm.gov.br/dadosabertos/SIGMINE/PROCESSOS_MINERARIOS/)
Alem disso, para aumentar a precisão dos resultados seria relevante buscar complementar os resultados obtidos com:
Imagens com uma classificação do satélite Sentinel-2 com resolução espacial de 10 metros. A Coleção BETA do MapBiomas 10 metros inclui mapas anuais de cobertura e uso da terra para o período de 2016 a 2022 (período de disponibilidade de imagens do satélite Sentinel-2): https://brasil.mapbiomas.org/mapbiomas-cobertura-10m/ .
Imagens com uma classificação supervisionado usando imagens de Sentinel-2 (exemplo com QGIS Semi-Automatic Classification plugin aqui: https://fromgistors.blogspot.com/2016/09/basic-tutorial-2.html).
Uma forma alternativa para visualização as mudanças entre anos seria um diagrama “Sankey”/“Alluvial”. Como exemplo, veja figura 3 no artigo “Rapid land use conversion in the Cerrado has affected water transparency in a hotspot of ecotourism, Bonito, Brazil” https://doi.org/10.1177/19400829221127087 .
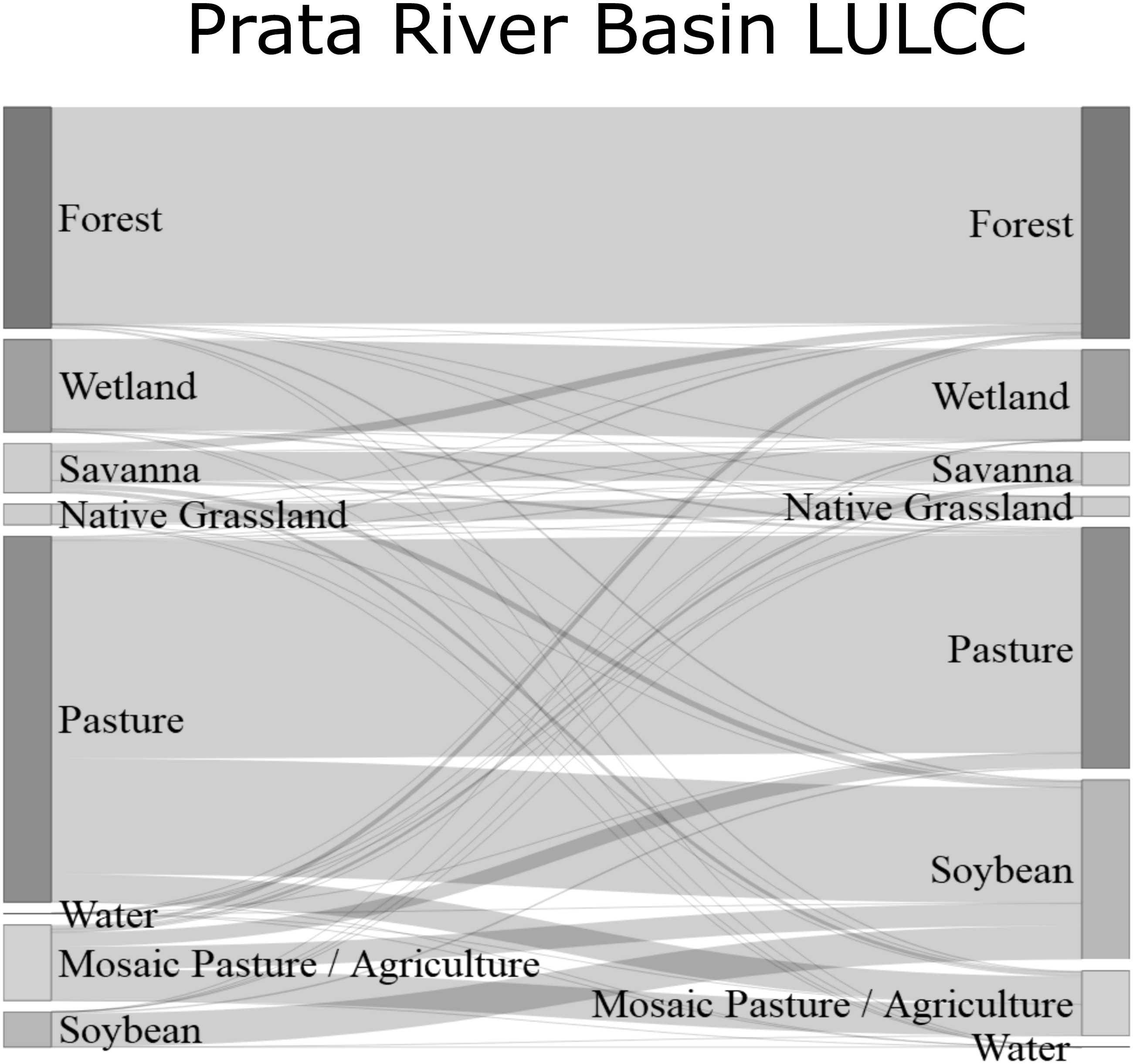
Figura 5.2: Diagrama Sankey mostrando a mudança de uso da terra na bacia do rio Prata entre 2010 (lado esquerdo) e 2020 (lado direto). Fonte: Figura 3. Chiaravalloti et. al. 2022. Tropical Conservation Science. doi:10.1177/19400829221127087
No R pode fazer com o pacote “networkD3” segue tutoriais: